大模型 API 推理全指南 | Ollama & OneAPI & vLLM & ChatTool
唠唠闲话
随着模型训练和推理技术的成熟,我们如何在资源有限的情况下更有效地利用这些技术?近年来,各种方案的出现极大地降低了科研门槛。从 vLLM 项目的内存优化到端侧小模型和代理运行超大模型,这些方案为模型推理提供了多样化的路径。
本文旨在探讨模型推理的技术方案,提供一个全面的入门指南,包括开源和闭源服务。
为什么用 API 接口?
自 2023 年 3 月推出 ChatGPT API 服务以来,几乎所有大模型服务和项目都支持 OpenAI 接口,这已然成为行业标准。使用 OpenAI 风格的 API 进行大模型推理有以下好处:
- 通用性:一套代码可适配调用各类大模型。
- 广泛支持:商用模型服务和开源项目均支持这一接口。
- 灵活性:API 化的大模型可在不使用时关闭服务,有效减少 GPU 资源占用。
- 易于配置:开源工具能轻松将任意模型服务转换为 OpenAI 接口规范的服务。
当然,这种方法也有局限,例如部分特性(如 system prompt 和 Function call)可能与某些模型不兼容。不过,诸如 Xinference 和 Langchain Tools 等项目可以弥补这些不足。
关联项目
教程从模型的性能效率和调用方式两个角度切入,涉及项目:
OneAPI 项目
OneAPI 是一个 API 管理和分发系统,支持几乎所有主流 API 服务。OneAPI 通过简单的配置允许使用一个 API 密钥调用不同的服务,实现服务的高效管理和分发。
讯飞/智谱/千问/Gemini/Claude,其模型调用方式各不相同,但借助 OneAPI 能统一转化为 OpenAI 格式。
官方提供了一键部署的 docker-compose 方案。部署完成后,访问 http://localhost:3000/ 并使用初始账号(用户名为 root,密码为 123456)进行登录,登录后根据提示修改密码。
类似的开源项目还有 AI GateWay 或者 LiteLLM等,各有优劣,但个人强推 OneAPI。
支持模型
下表列举了几个 OneAPI 支持的 API 服务,完整的模型列表参见 OneAPI 官方仓库。
| 所属公司 | 模型 | 文档地址 | 备注 |
|---|---|---|---|
| 面壁智能 | 智谱 glm | 智谱 API 文档 | 新用户 1B Token 免费额度,1个月有效期 |
| 阿里云 | 通义千问 Qwen | 千问 API 文档 | 新用户 1B Token 免费额度,半年有效期 |
| 百川智能 | 百川大模型 | 百川 API 文档 | 新用户 8元免费额度,3个月有效期 |
| 讯飞 | SparkDesk | 讯飞 API 文档 | 新用户 100K Token 免费额度,1年有效期 |
| 谷歌 | Gemini/PaLM2 | Google API 文档 | 提供免费版 API,存在使用限制 |
| OpenAI | GPT | OpenAI API 文档 | 网页版可免登录使用,API 需国外银行卡 |
| 微软 | Azure | Azure API 文档 | 需注册 Azure 账号,支持国内 visa 信用卡或双币卡 |
添加渠道
集成各类 API 服务添加到 OneAPI 中:
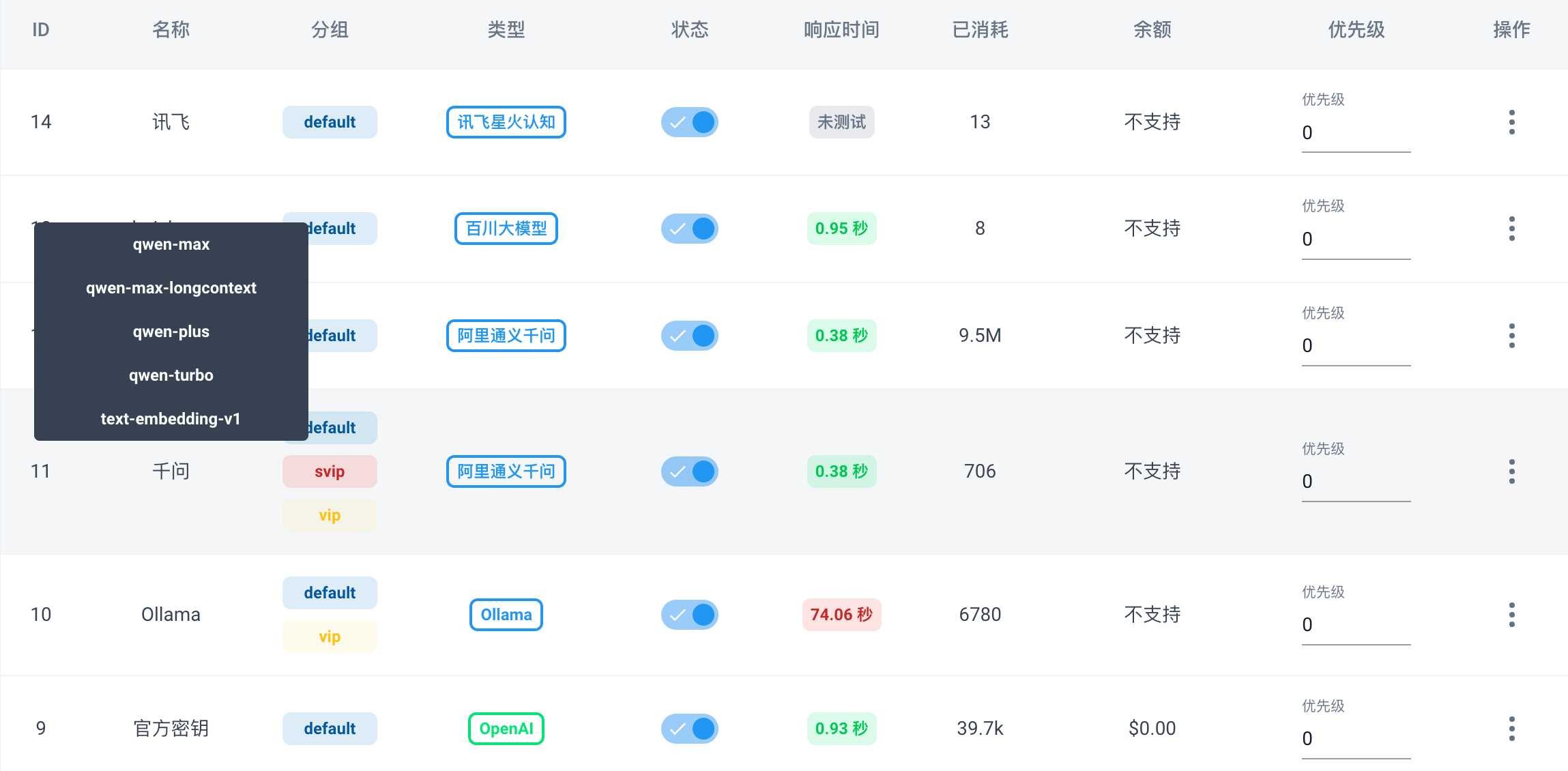
以谷歌的 Gemini 为例:点击渠道 => 新建渠道
内容说明:
- 渠道名称:自定义
- 渠道 API 地址:官方 API 地址或者反向代理地址
- 用户组:这个选项是给号商用的,可以不管
- 模型:填入用户调用模型
- 密钥:API 密钥
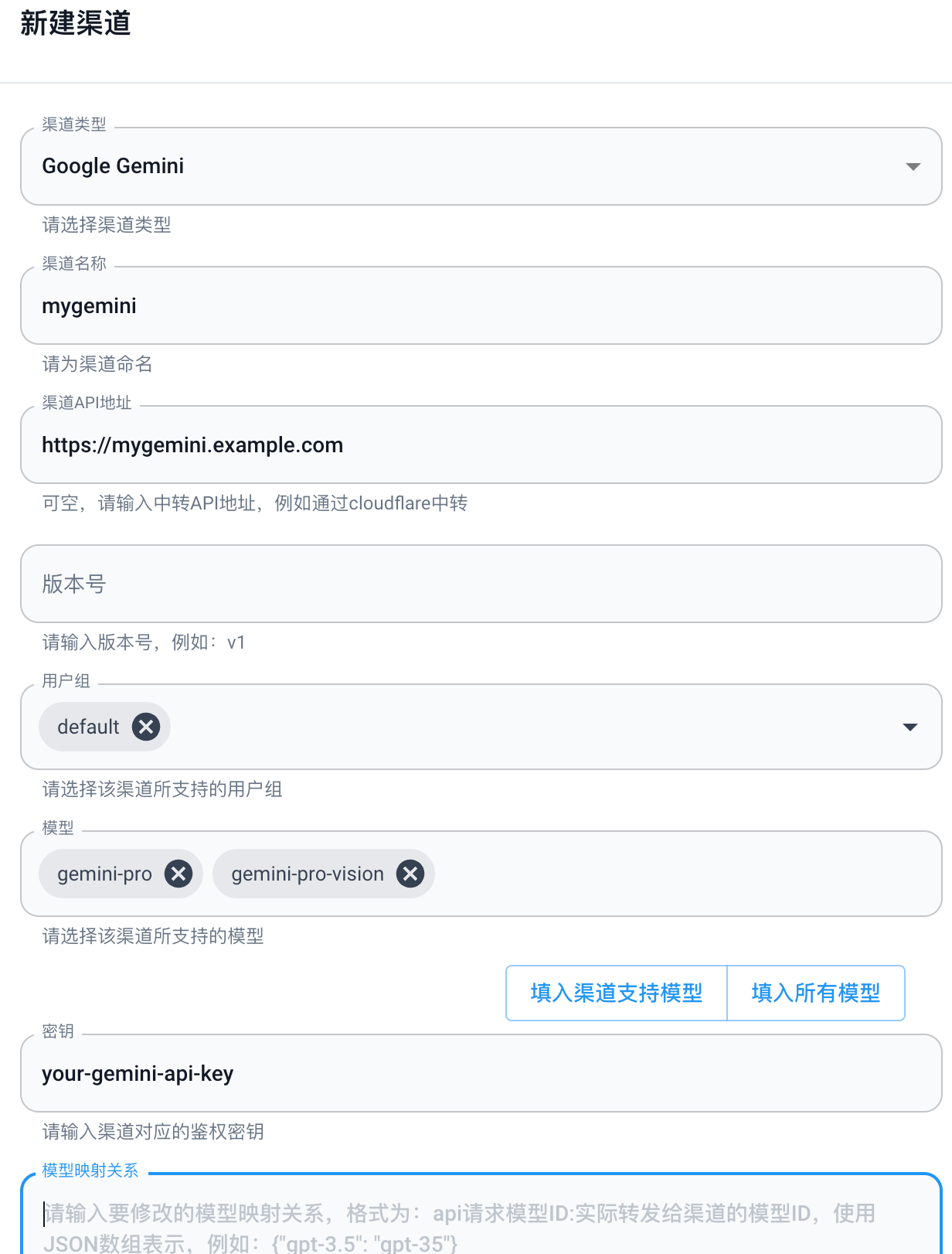
- 模型映射关系:用户调用模型 => 实际调用模型。比如
{ "dall-e-3": "cogview-3" }:当用户请求dall-e-3时,实际请求了cogview-3模型。
模型映射关系在一些场景很有用,比如:
- LlamaIndex 中使用 OpenAI 对象,非 GPT 的模型名称会报错
- lobe-hub 自带的绘图插件只支持调用
dall-e-3模型
创建密钥
添加渠道后,点击令牌,新建令牌,创建密钥,复制密钥。密钥作用等同于 OpenAI 的 API。
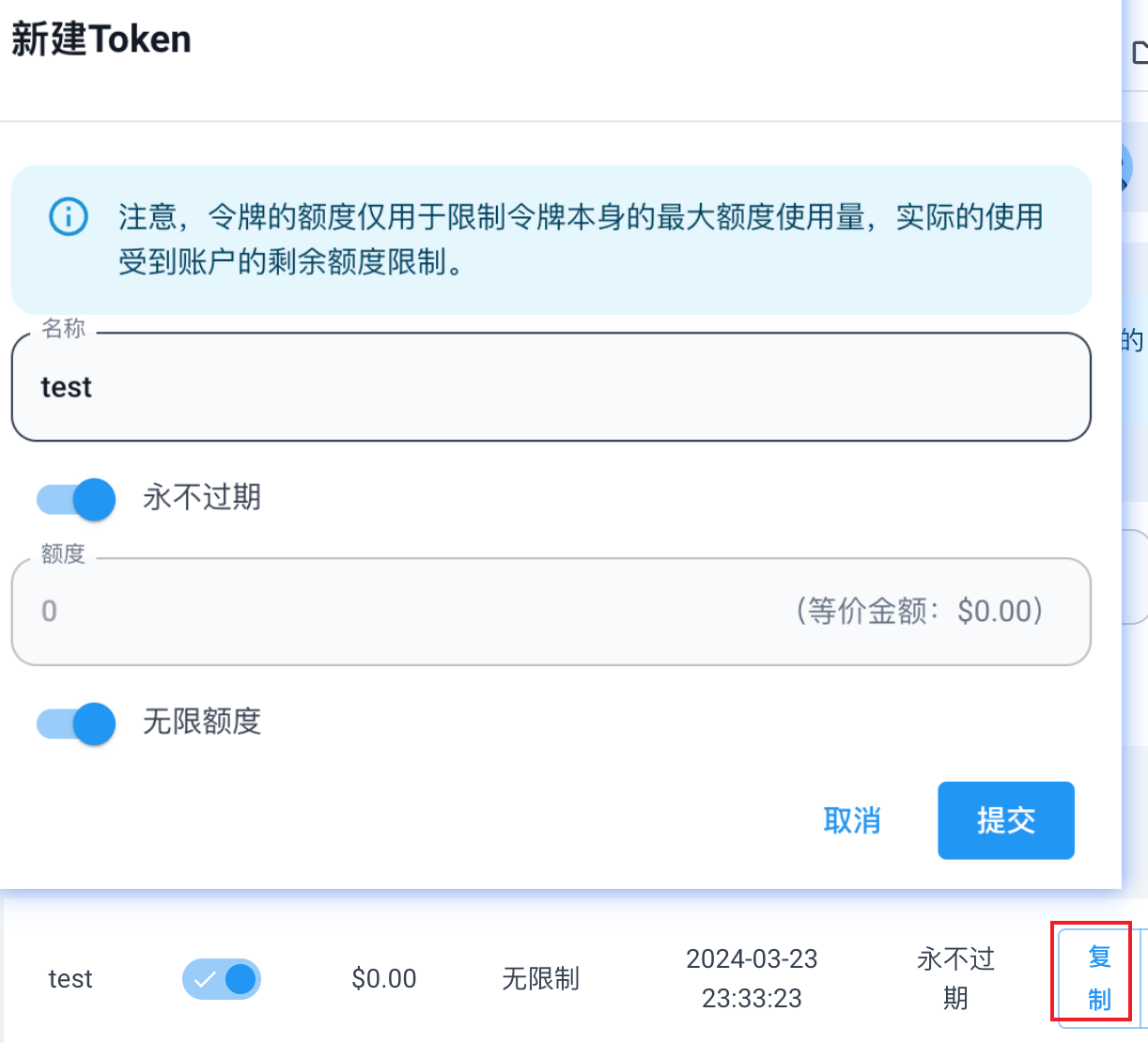
渠道存在优先级,如果同一模型有多个渠道支持,OneAPI 会按权重使用不同渠道。但 root 用户可通过 -k 指定渠道,比如下边添加了两个渠道:

通过 sk-xxxxxx-1 指定 ChatAnywhere 渠道,通过 sk-xxxxxx-2 指定 bichat 渠道。
除此之外,你可以让每个模型只对应一个渠道,这样指定模型时,渠道也是确定的。
创建密钥后,走服务地址作为 API 代理地址,比如在本地启动服务,走 localhost:
1 | OPENAI_API_BASE=http://localhost:3000/v1 |
分配用户
OneAPI 支持多用户管理,root 和管理员能管理模型渠道,配置额度。普通用户则在注册后,通过添加兑换码导入额度。
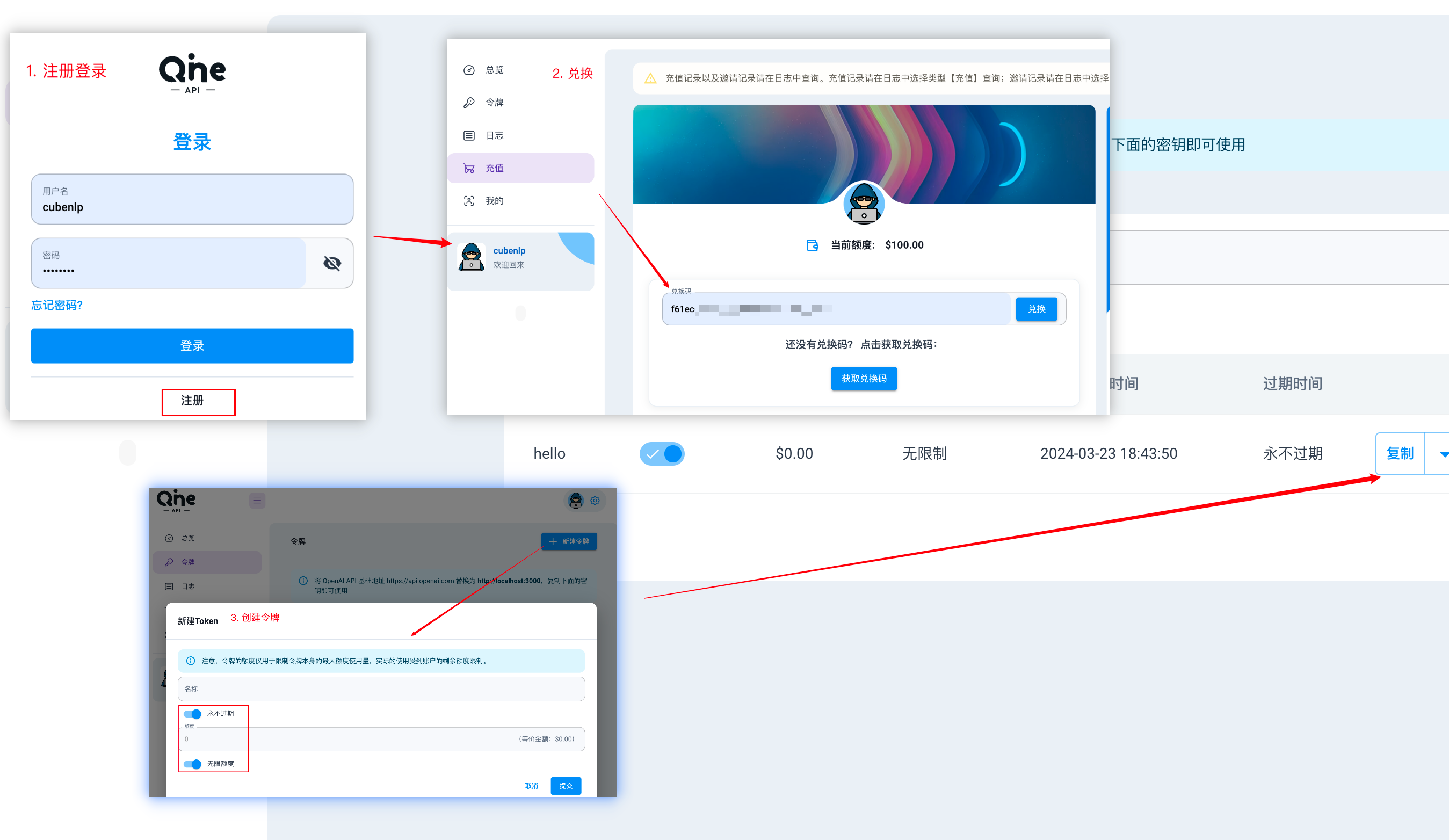
创建密钥的过程与前边一致。
配置 Nginx
假设服务运行在 3000 端口,配置访问域名为 one-api.example.com
1 | server { |
类似可配置 https 的访问。
反向代理
反向代理主要用于 OpenAI, Gemini, Claude 等限制国内 IP 访问服务。以 Gemini 为例,在支持访问的服务器上配置 Nginx:
1 | server { |
然后将代理链接 your.domain.com 并导入 OneAPI 的 Gemini 渠道。类似方法适用于对 Claude 和 OpenAI 等服务的转发。
模型代理站
如果硬件资源不足,可以用代理站作为补充。优点是省事,访问快,支持超大模型。缺点是数据经过一手,安全隐患增加一层,使用代理站更多出于实验方便。这里推荐几个站点:
| 代理站 | 服务地址 | 模型支持 | 备注 |
|---|---|---|---|
| Chatanywhere | chatanywhere/GPT_API_free | OpenAI 系列 | 速度快,价格低 |
| 沃卡 | wokaai.com | OpenAI/Claude/Gemini/Midjourney | 基于 OneAPI 项目 |
| Chandler.ai | ChandlerAi | OpenAI/Claude/Grok 等 | 需国外信用卡 |
| NeutrinoAPP | neutrinoapp.com | OpenAI/开源模型 | 需国外信用卡 |
| monsterapi.ai | monsterapi.ai | 仅开源模型 | 支持模型微调,需国外信用卡 |
| Predibase | Predibase AI | codellama/llama/gemma/mixtral 等 | 支持模型微调,需国外信用卡 |
后两个网站提供对开源模型的微调和推理服务,支持多种模型和微调方式,比如 MonsterAPI:
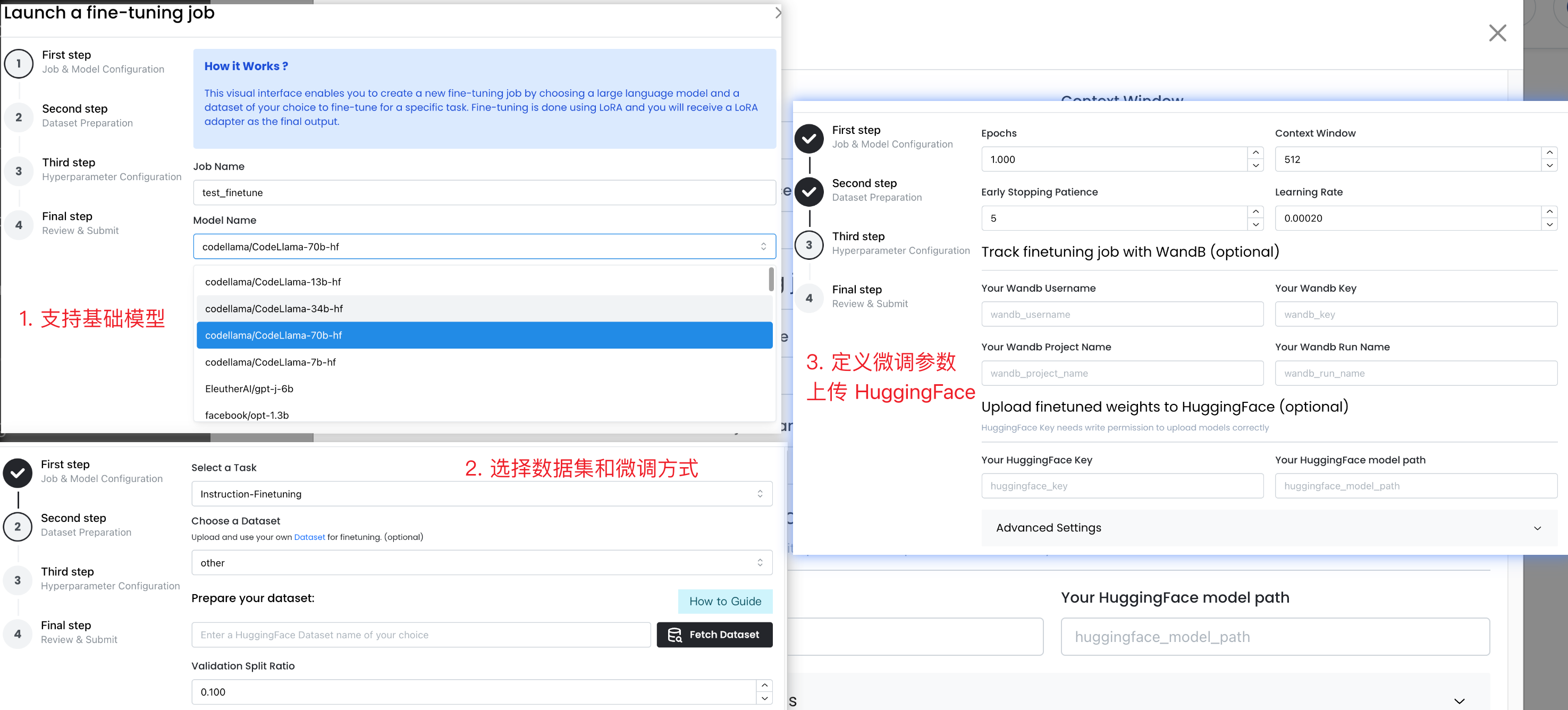
vllm
前边讲了闭源 API 转成 OpenAI 风格的方式,下边介绍开源模型如何以 OpenAI Style 启动,继而也能导入到 OneAPI 统一管理。这方面我们讲两个比较有代表性的项目。
vLLM 是去年6月推出的一个大模型推理加速框架,通过 PagedAttention 高效管理 attention 中缓存的张量,实现了比 HuggingFace Transformers 高 24 倍的吞吐量。vLLM 支持的开源模型包括 Llama,百川,千问等模型,也支持基于这些模型架构训练或微调得到的模型,比如 Lemur:

vLLM 提供了一个 OpenAI 风格的 API 服务,比如启动百川模型
1 | # pip install vllm |
参数说明(Ref:官方文档 - OpenAI Compatible Server):
--model:模型路径,本地路径需加上--trust-remote-code参数--tensor-parallel-size:模型使用的 GPU 数目--served-model-name:用户访问的模型名称--api-key:API 密钥,可不填,允许任意密钥访问--port:服务端口
vLLM 还支持 推理量化,加载 Lora 参数和分布式推理等。
类似 vllm 的项目还有 LightLLM 和 FasterTransformer等。
Ollama
GGUF 格式以及 Ollama 更深入的介绍,另外再开帖子讨论
相比 vllm 或者直接使用 huggingface 的模型推理 Pipeline。ollama 极大降低了模型使用门槛:
- 零 Python 代码以 OpenAI 风格启动模型
- 支持在普通电脑上运行量化模型,低显存占用,支持 CPU 推理。
从 32 位量化到 4bit,会一定程度降低模型的表现,一种取舍,涉及模型压缩技术。
部署及使用
Docker 部署:https://ollama.com/blog/ollama-is-now-available-as-an-official-docker-image
API 文档:https://github.com/ollama/ollama/blob/main/docs/api.md
推荐使用 docker-compose 部署一键启动服务,方便修改端口,GPU 配置以及模型下载路径等:
1 | version: '3.8' |
http://localhost:11434 为 API 服务地址。
创建别名:
1 | alias ollama='docker exec -it ollama ollama' |
基本操作:
1 | # 拉取模型,比如千问 |
GGUF 格式
GGUF: GPT-Generated Unified Format
GGUF:GPT 生成的统一格式
文档:https://github.com/ggerganov/ggml/blob/master/docs/gguf.md
模型量化方式:Which Quantization Method Is Best for You?: GGUF, GPTQ, or AWQ
GGUF 由llama.cpp团队介绍。它是一种为大型语言模型设计的量化方法。它允许用户在 CPU 上运行LLMs,同时通过提供速度改进将某些层卸载到 GPU。
GGUF 对于在 CPU 或 Apple 设备上运行模型的用户特别有用。在 GGUF 上下文中,量化涉及缩小模型权重(通常存储为 16 位浮点数)以节省计算资源。
GGUF 是一种更有效、更灵活的存储和用于LLMs推理的方式。它专为快速加载和保存模型而量身定制,采用用户友好的方法来处理模型文件。
开发者:Georgi Gerganov
文档:https://github.com/ggerganov/ggml/blob/master/docs/gguf.md
HuggingFace 大佬 Tom Jobbins 对大量的主流模型进行了量化。
量化模型的仓库地址:https://huggingface.co/TheBloke
模型列表
支持列表:https://ollama.com/library
Embedding:Embedding models
以 codellama 为例:
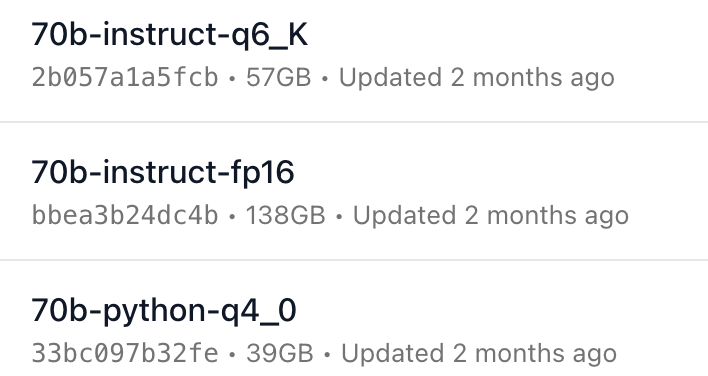
主要的关键字:模型参数量,模型类型,量化级别,量化方式。
| 模型类型 | 说明 |
|---|---|
instruct |
Fine-tuned to generate helpful and safe answers in natural language |
python |
A specialized variation of Code Llama further fine-tuned on 100B tokens of Python code |
code |
Base model for code completion |
内存占用方面,千问 Qwen-72b-1.5 模型,4-bit 量化,推理显存 40G 左右,两张 3090 可用:

加载本地模型
文档:https://github.com/ollama/ollama/blob/main/docs/import.md
启动 hf 模型
- safetensor 格式
- GGUF 格式
缺陷
- 切换模型问题
- 首次加载问题
- 并发问题(特性已更新):https://github.com/ollama/ollama/pull/3418
数据量大,当前仍需要 vllm 等项目。
flask
最后,如果需要对 API 进行灵活定制,可以用 flask 或 FastAPI 手写服务。举个例子,以 OpenAI 风格启动 HuggingFace 的 Embedding 模型:
1 | from flask import Flask, request, jsonify |
测试请求:
1 | curl -H "Content-Type: application/json" \ |
除了常规策略,还有基于 ChatGPT 网页端进行逆向白嫖的,比如 FreeGPT35,GPT4Free 和 coze-discord 等,当前暂不讨论。
ChatTool
用 API 跑数据可以直接用官方库 openai,也可以用 ChatTool,基于 API 的封装,支持多轮对话,异步处理数据等。
先进行配置:
1 | export OPENAI_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" |
或者在代码中设置:
1 | import chattool |
举两个例子。
-
将数字翻译为罗马数字,串行处理数据,缓存文件为
chat.jsonl:1
2
3
4
5
6
7
8
9
10
11
12def data2chat(msg):
chat = Chat()
chat.system("你是一个熟练的数字翻译家。")
chat.user(f"请将该数字翻译为罗马数字:{msg}")
chat.model = "gpt-3.5-turbo" # 默认模型
# 注意: 在函数内执行 getresponse
chat.getresponse(max_tries=3)
return chat
checkpoint = "chat.jsonl" # 缓存文件的名称
msgs = ["1", "2", "3", "4", "5", "6", "7", "8", "9"]
chats = process_chats(msgs, data2chat, checkpoint)
# chats = load_chats(checkpoint) -
用不同语言打印
hello world,并行处理数据1
2
3
4
5
6
7
8
9from chattool import async_chat_completion, load_chats, Chat
langs = ["python", "java", "Julia", "C++"]
def data2chat(msg):
chat = Chat()
chat.user("请用语言 %s 打印 hello world" % msg)
# 注意:不需要 getresponse 而交给异步处理
return chat
async_chat_completion(langs, chkpoint="async_chat.jsonl", nproc=2, data2chat=data2chat)
chats = load_chats("async_chat.jsonl")在 Jupyter Notebook 中运行,需要使用
await关键字和wait=True参数:1
await async_chat_completion(langs, chkpoint="async_chat.jsonl", nproc=2, data2chat=data2chat, wait=True)
以上,将模型整合到 API 网关,统一服务接口供代码调用。这样,我们就能轻松地集成各类大模型,也省去配置环境的麻烦。
 wechat
wechat alipay
alipay





