DB-GPT | 实践指南
唠唠闲话
DB-GPT 是一个开源的 AI 原生数据应用开发框架 AI Native Data App Development framework with AWEL and Agents。该项目旨在构建大模型领域的基础设施,通过开发:
- 多模型管理(SMMF, Service-oriented Multi-model Management Framework)
- Text2SQL 效果优化
- RAG 框架以及优化
- Multi-Agents 框架协作
- AWEL(智能体工作流编排)
等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。数据 3.0 时代,基于模型、数据库,企业/开发者可以用更少的代码搭建自己的专属应用。
当前发展趋势的变化:
- 服务类型的变化:IaaS/PaaS/SaaS => AaaS
- 开发模式的变化:DevOps => LLMOps
DB-GPT 官方文档:
注:中文文档更新不全,且存在错误,建议以英文文档为准。
项目特性
项目示意图:
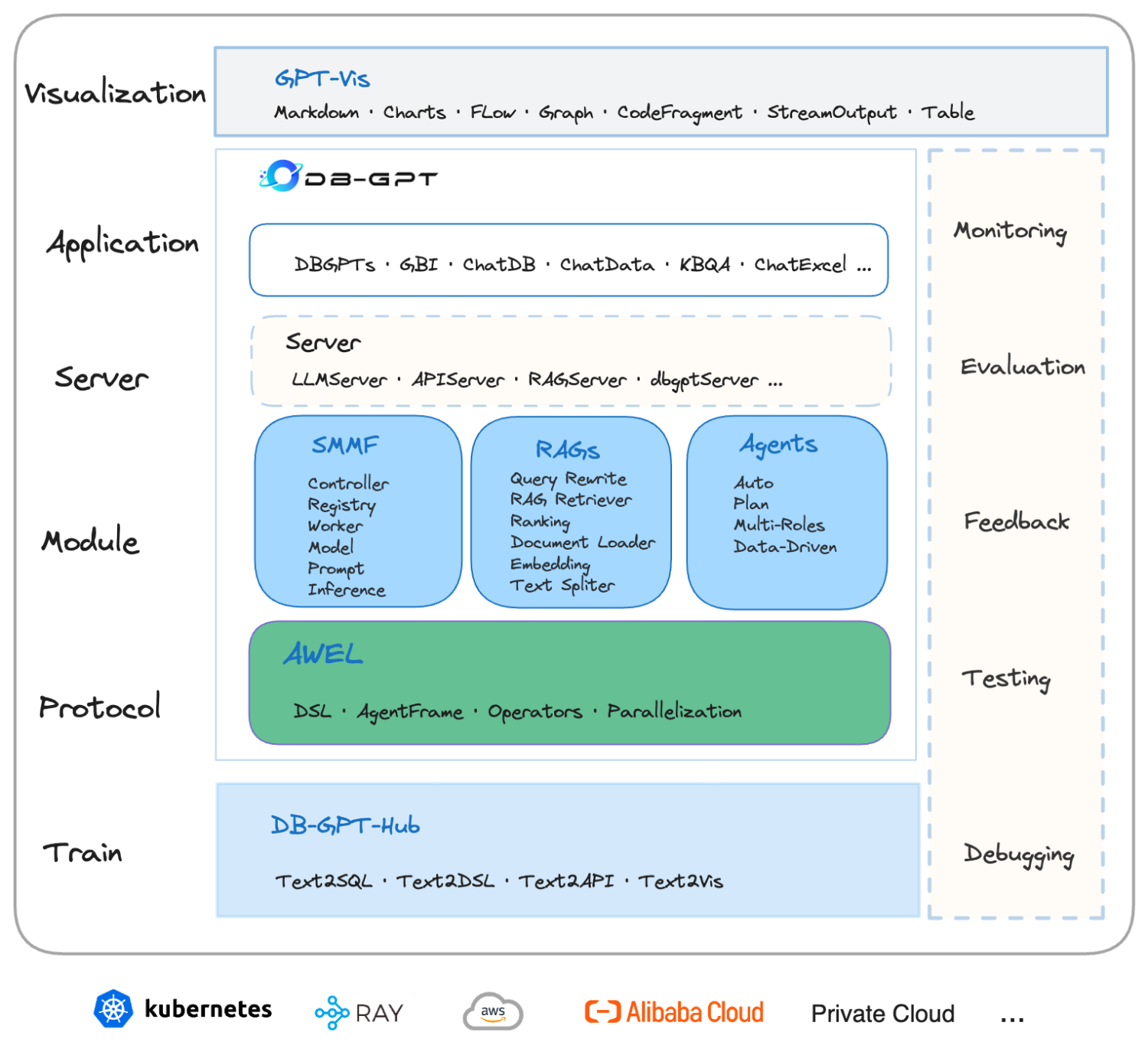
| 名词 | 说明 |
|---|---|
| DB-GPT | 一个开源的 AI 原生数据应用开发框架 |
| AWEL | Agentic Workflow Expression Language, 智能体工作流表达式语言 |
| AWEL Flow | 使用智能体工作流语言编排的工作流 |
| LLMOps | 大语言模型操作框架,提供标准的端到端工作流程,用于训练、调整、部署和监控 LLM,以加速生成 AI 模型的应用程序部署 |
| Plugin | 插件, 主要用来完成某一个或者某一类具体的动作。 |
| Datasource | 数据源,比如 MySQL、PG、StarRocks、Clickhouse 等。 |
| Text2SQL/NL2SQL | Text to SQL,利用大语言模型能力,根据自然语言生成 SQL 语句,或者根据 SQL 语句给出解释说明 |
| KBQA | Knowledge-Based Q&A 基于知识库的问答系统 |
| GBI | Generative Business Intelligence 生成式商业智能,基于大模型与数据分析,通过对话方式提供商业智能分析与决策 |
| Embedding | 将文本、音频、视频等资料转换为向量的方法 |
| RAG | Retrieval-Augmented Generation 检索能力增强 |
博客定位
博客将从实践角度,围绕以下几个要点介绍 DB-GPT 的特性:
- 支持的知识库有哪些,怎么添加,以及怎么使用
- 智能体的构建方式,以及如何使用 AWEL Flow
- 前端的可视化,以及与用户的交互方式
实践的 DB-GPT 版本为 0.5.0,这个版本开始为 DB-GPT 第一个长期维护的版本。
服务部署
DB-GPT 提供了。这部分本身也可以单独作为一个工具使用。
0. 安装环境
通过源码安装,其中 Python 版本建议小于 3.10
1 | git clone https://github.com/eosphoros-ai/DB-GPT.git |
如果遇到环境依赖问题,再根据报错信息灵活处理。
1. 模型管理
启动模型控制器:
1 | dbgpt start controller # 默认端口 8000 --port 修改 |
以下假设服务在 172.23.148.37 下启动,其他模型则通过局域网的其他服务器启动。
添加本地模型
启动本地模型,比如 chatglm3-6b:
1 | # CUDA_VISIBLE_DEVICES=0,1 |
其中 --controller_addr 填写控制器所在的服务器地址,如果是本地则填写 127.0.0.1。
回到控制器服务器,查看模型列表:
1 | ❯ dbgpt model list |
测试模型:
1 | ❯ dbgpt model chat --model_name chatglm3-6b |
注意事项:
- 一个端口只能注册一个模型,注册后,该端口会启动一个 WorkerManager 服务
- 模型关闭后,
dbgpt model list仍会显示注册过但已关闭的模型,其Healthy为False。同样地,网页端也仍会显示
- Worker 默认会使用所有可用的 GPU,且
--num_gpus参数似乎没用,还是得用CUDA_VISIBLE_DEVICES控制。 - 如果指定了
worker_type,则参数规则会改变,比如vllm是用--tensor_parallel_size参数指定 tensor 并行的数量,用--num_gpus参数会报错。
添加嵌入模型
添加 Embedding 模型:
1 | dbgpt start worker --model_name text2vec-large-chinese \ |
这里 worker_type 设置为 text2vec。
vLLM 加载模型
这部分需要安装 vllm 模块,使用 pip install -e ".[vllm]" 安装。
1 | dbgpt start worker --model_name chatglm3-6b \ |
似乎没有正常启动,尽管推理时显存有占用,但回答结果空白,可能需要设置停止词之类的。
添加 API 模型
文档这部分写得一言难尽,这些参数的规则需要结合 .env 文件和网页端推理出来。
添加 OpenAI 模型:
1 | dbgpt start worker --model_name chatgpt \ |
添加智谱模型:
1 | dbgpt start worker --model_name zhipu_proxyllm \ |
添加 OpenAI Embedding 模型:
1 | dbgpt start worker --model_name openai-embedding \ |
谷歌,微软等模型的添加方式类似。
实测环境变量也有影响。
模型推理
模型能以兼容 OpenAI 的方式推理,具体地,先启动 API Server 服务:
1 | dbgpt start apiserver --api_keys EMPTY --controller_addr http://127.0.0.1:8000 # 默认值,可以不填 |
参数说明:
--api_keys:API 的 key,如果有多个,用逗号分隔;如果不填写,则允许所有密钥;这里将密钥设置为EMPTY这个单词。--controller_addr:控制器地址,可不填,与上边等同。--port:端口号,默认 8100。--host:监听的地址,默认0.0.0.0。
测试模型:
1 | curl http://127.0.0.1:8100/api/v1/chat/completions \ |
吐槽一下:官方的中文文档,这部分把端口的规则写反了。。。
2. 启动服务
加载 Embedding 模型
需要下载 Embedding 模型才能正常启动,尽管启动选项提供了 --remote_embedding 来使用 Worker 中的模型,但实际运行会报错,待处理。
下载模型到仓库目录:
1 | # cd DB-GPT |
配置环境变量
复制环境变量文件并修改
1 | cp .env.template .env |
一个简单的配置例子,可以直接粘贴,或者修改对应选项:
1 | # .env |
启动服务:
1 | dbgpt start webserver --light # 默认端口 5000 |
由于使用多模型管理,这里必须用 --light 参数,将模型加载交给控制器,而不是使用 .env 的模型配置。其中变量 LLM_MODEL 将用作默认模型,请确保模型列表中有该模型。
这里还有些参数,后续有需要再补充。
变量的读取规则尚不清楚,应该是:环境变量 >
.env文件 > 默认值。待确认。
服务介绍
通过 服务器IP:5000 访问服务,如下图所示,启动了四个模型:
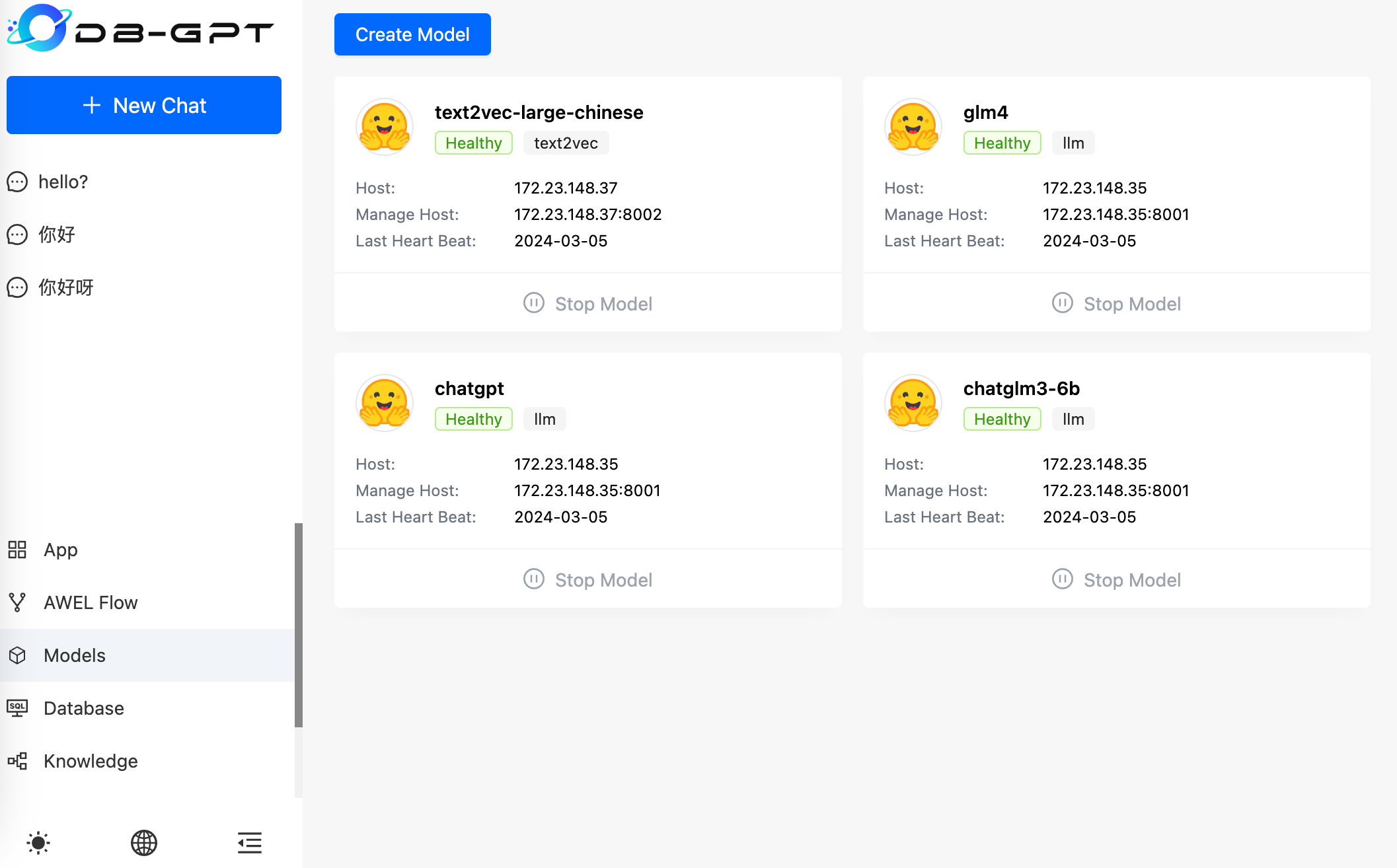
左侧为对话列表,下方包括五个模块:
- APP 应用
- AWEL Flow 智能体工作流
- Models 模型管理
- Database 数据库
- Knowledge 知识库
从 0.5.0 版本开始,DB-GPT 项目原生集成了 data-centric 程序的管理和分发。dbgpts 项目管理和分享的资源分为以下几类:
- 应用程序:使用 DB-GPT 框架开发的原生智能数据应用程序。
- 工作流:使用 AWEL(Agentic Workflow Expression Language)构建的工作流程。
- 智能代理:可以执行各种任务的智能代理。
- 操作算子:可以在工作流程中使用的基本操作单位。
以上主要介绍了服务部署和模型管理。下边我们将在实战过程中,介绍这些板块的用法。
知识问答
第一部分,针对文件知识库的 RAG 问答,针对结构化知识库的工具问答。
知识库问答
Q:支持的知识库有哪些,怎么添加,以及怎么使用。
-
支持:纯文本、URL抓取、PDF、Word、Markdown 等多种文档类型
-
创建对话:选择知识库对话,结合知识库的文档进行问答。初始 Prompt 可以在知识库中修改,聊天会自动使用 RAG 抽取信息,拼接到 Prompt 中。
-
在知识库对话下,允许用户直接上传文件进行对话,且默认会触发文档的总结能力。上传的文件也会传入该知识库。
-
潜在问题:.py 等文件直接导入会显示 TODO。直接上传也一样
-
大文件导入比较久,RUNNING 默认用了 CPU 推理,怎么修改。
-
空白对话也有默认 Prompt,暂时不知道怎么改。
1 | PROMPT_SCENE_DEFINE_EN = "You are a helpful AI assistant." |
总结:能够按知识库进行归类,进行问答。待修缮:文件导入,Prompt 修改,GPU 设置。
注:从模型调用结果来看,其结合了 RAG 检索知识库和模板拼接。
数据问答
1 | pip install cryptography |
添加数据后,在 ChatData 板块进行问答。会根据用户问题,生成代码,进行回答。
亲测除了 chatglm3-6b,基本都能完成。界面的 Editor 支持对代码记性修改。
Q:生成过程是怎么进行的?
A:从日志可以看出,基于形如下边的 Prompt
1 | 请根据用户选择的数据库和该库的部分可用表结构定义来回答用户问题. |
思考过程:
1 | {"thoughts": "为了查询前十个学生的信息,我们可以使用 `SELECT` 语句从 `students` 表中选择 `student_id` 和 `student_name` 列,并按照 `student_id` 升序排列。", "sql": "SELECT student_id, student_name FROM students ORDER BY student_id LIMIT 10","display_type": "Data display method" |
系统背后:
1 | editor_sql_run:{'db_name': 'case_1_student_manager', 'sql': 'SELECT student_id, student_name FROM students ORDER BY student_id LIMIT 10'} |
Q1:ChatDB 做什么用的,似乎只能看到结构,不能执行动作。
Q2: ChatExcel 似乎当成数据库来操作了
Q3: ChatDashboard 支持分析需要的功能,但当前的前端页面容易丢失信息。
还有个问题,所有对话,不支持修改历史记录,或者重新生成这一类操作。
开发设计
1 | pip install Poetry |
目前支持三个内容:
- 插件开发,比如调用百度搜索
- AWEL 流
- 应用构建
BIChat:
直接启动,推理停止词
1 | # BIChat |
1 | dbgpt start worker --model_name bichat \ |
API 启动
示例:
前端页面魔改
npm install @emotion/react @emotion/styled
npm config get registry
npm config set registry https://r.cnpmjs.org
npm install @mui/material @mui/icons-material
 wechat
wechat alipay
alipay





