服务器硬盘维护 | 学习笔记
唠唠闲话
最近服务器硬盘故障,在修复过程中,学习了一些操作,这里做个记录。
U 盘启动盘
下载镜像
Ubuntu 的版本命名遵循 “Adjective Animal” 的模式,即 “形容词+动物” 名称,每个版本都有一个官方的代号。Ubuntu 的版本还分为 LTS 和普通版,LTS 是“Long Term Support”的缩写,意味着这个版本将获得长期的支持,通常是五年。普通版本通常每六个月发布一次,支持期限为九个月。
写这篇博客的时候是 2024 年,因此建议下载至少 20.04 LTS 版本的 Ubuntu 镜像,这是一个长期支持版本,支持到 2025 年。
-
20.04 LTS “Focal Fossa”
- 发布时间:2020年4月
- “Focal”意味着“中心的”或“焦点”,“Fossa”是马达加斯加的一种猫科动物,暗示该版本稳定且聚焦于长期支持特性
- 下载地址:https://releases.ubuntu.com/focal/
-
22.04 LTS “Jammy Jellyfish”
- 发布时间:2022年4月
- “Jammy”在英国俚语中意思是“非常幸运的”,“Jellyfish”即水母,可能是指新的长期支持版本在稳定性与新特性引入方面的“幸运平衡”
- 下载地址:https://releases.ubuntu.com/jammy/
下载 Ubuntu 22 镜像:
1 | wget -c https://releases.ubuntu.com/jammy/ubuntu-22.04.4-desktop-amd64.iso |
制作启动盘
从 Rufus 官网下载 Rufus 工具,该工具仅支持 Windows 系统:
1 | wget -c https://github.com/pbatard/rufus/releases/download/v4.4/rufus-4.4.exe |
打开后,选择镜像,和 U 盘,然后开始制作启动盘。
设置持久化分区存储,这样在 U 盘上安装软件和保存文件都会被保留。如果该 U 盘仅用于系统盘,可将持久分区拉满。下图保留了部分空间用于日常存储。
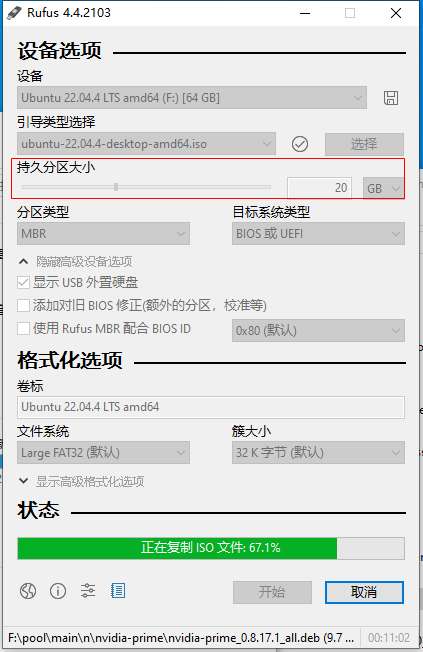
如果不设置持久存储,启动 U 盘时将以只读模式加载操作系统,同时使用 RAM(随机访问存储器)作为临时的写入空间。这意味着使用过程中产生的数据(如临时文件、系统日志等)都存储在内存中,而不是 U 盘或硬盘上。
注:Rufus 的持久性功能被明确标记为 EXPERIMENTAL,如果希望更稳定的持久性功能,可以尝试其他工具,如 UNetbootin。
启动 U 盘
开机按 F2 或 Delete 进入 BIOS 设置,找到启动项,将 U 盘启动项调整到第一位。开机后,选择语言,并选择 “试用 Ubuntu” 进入系统。
输入 ctrl + alt + t 打开终端,输入 df -h 查看硬盘信息,可以看到系统目录 / 由持久化存储分区 /cow 挂载。
软件配置
可将 U 盘当作移动的系统盘,随时随地使用。
根据需要给 U 盘安装必要软件,参考教程 Ubuntu 教程(一) | 必备软件的安装和配置。
如果在校园网下无法联网,通过局域网 IP 安装联网脚本:
1 | # 如果是 zsh 用户,使用 | zsh |
默认的 APT 源不完整,搜索不到 testdisk 等应用,需要修改。以下为 22 版本的 apt 源:
1 | # cd /etc/apt |
更改 apt 源后,开始安装软件:
1 | sudo apt update |
实测用 Rufus 安装的 U 盘启动盘,在启动时,有可能会重置主机名和默认登录用户。因此建议创建新用户,并在新用户上配置环境。
网络设置
Netplan 会读取 /etc/netplan/ 目录下的所有以 .yaml 结尾的文件来构建整个系统的网络配置。如果目录中有多个配置文件,Netplan 会按字母顺序合并这些文件。
查看默认 netplan 配置文件:
1 | # cat /etc/netplan/01-network-manager-all.yaml |
网络配置由 NetworkManager 服务管理,NetworkManager 是一个动态网络管理工具,它可以自动检测和配置网络连接,使得用户在大多数情况下无需手动配置网络。
部分情况需手动修改,可通过以下方法之一来查看系统中所有网络接口的名称:
- 执行
ip link或ip a命令在终端中查看。 - 使用
ifconfig命令(如果已安装net-tools包)。
举个例子:
1 | network: |
接口名称的含义:
en表示以太网(Ethernet)。o表示 onboard(板载设备)。s表示 hotplug slot(热插槽)。x表示 MAC地址(通常用于无法通过其他方式分类的情况)。- 数字表示物理位置或者是内部编号,如
eno1通常指的是第一个板载以太网接口。
修改配置后,执行 sudo netplan apply 使配置生效。
修改日志规则
默认情况下,Ubuntu 系统日志使用 rsyslog 服务来记录系统事件,按时间轮转。
1 | cd /etc/logrotate.d |
内容形如:
1 | /var/log/syslog |
前边是指定的日志文件,大括号 {} 内的是对这些文件应用的具体规则:
rotate 4:保留最新的4个轮替文件。超过这个数量的旧文件会被删除。weekly:日志文件将每周轮替一次。missingok:如果日志文件不存在,不会报错。notifempty:如果日志文件为空,不进行轮替。compress:轮替的日志文件将被压缩(默认使用gzip)。delaycompress:压缩操作将延迟到下一次轮替周期。sharedscripts:这个选项意味着postrotate脚本将只执行一次,而不是对每个日志文件执行一次。postrotate/endscript:这是一对指令,定义了在日志文件轮替后需要执行的脚本。
比如将 weekly 改为 size 100M 选项,指定日志文件达到一定大小时进行轮替,避免异常占用。
执行 sudo logrotate -f /etc/logrotate.conf 使配置生效。
异常处理
U 盘运行 ddrescue 时,没限制日志大小,把电脑卡死了,导致重启一直卡在光标处进不了系统。
在论坛翻到了一个进入命令行系统的方案:Ubuntu boots to a black screen with blinking a underscore character after release upgrade。
开机选择安全模式,卡在光标处的时候,按 Ctrl + Alt + F1 或 Ctrl + Alt + F3 切换到命令行模式。
最后通过命令行发现了该问题: U 盘的 /var/log/syslog 和 /var/log/kern.log 把持久化内存撑爆了,导致系统无法正常启动。
清理并刷新系统日志:
1 | cd /var/log |
重新输入 df -h 查看硬盘占用信息。
备份系统
Rufus 重装后有两个分区,一个是只读的 squashfs,另一个是持久化的 ext4。
这种特别设计用于支持 Ubuntu Live 环境中的数据持久性。在这种环境中,系统文件是以特定的方式存储和管理的,以允许从 read-only 的 Live 系统(如 ISO 映像)启动,同时能保存用户的修改和系统的更新到一个持久的存储空间。
备份硬盘,例如:
1 | sudo dd if=/dev/sda of=/path/to/backup.img bs=4M status=progress |
重装系统
交换机网络重启
服务器之间加装了交换机,共享文件存储。有时会遇到某个设备与其他设备无法通信,此时可以尝试重启该设备的网络:
1 | ip addr # 确认网络接口 |
硬盘维护
硬盘维护策略和分区备份方案。
查看硬盘信息
获取硬盘挂载信息的几个命令:
| 常见命令 | 用处 |
|---|---|
lsblk |
列出所有可用的存储设备及其分区,包括设备的挂载点、大小等信息 |
fdisk -l |
显示磁盘分区表信息,包括分区大小、类型等(需 sudo 权限) |
blkid |
列出所有设备的 UUID 等信息,也可以用于识别设备类型 |
pvdisplay |
显示物理卷信息 |
vgdisplay |
显示卷组信息 |
lvdisplay |
显示逻辑卷信息 |
lshw |
列出系统的硬件配置的命令,-short 选项以简短格式输出硬件详情 |
lsblk -d -o name,rota |
查看硬盘类型,0 代表 SSD,1 代表 HDD,也即旋转设备 |
举个例子,通过 fdisk -l 来判断设备信息:
1 | root@rex-pc:/home/rex# fdisk -l |
比如这里装了两个系统:/dev/sda 是一个 120GB 的 Tigo SSD 硬盘,有 4 个分区,挂载 Windows 系统;/dev/sdb 是一个 120GB 的 SanDisk 硬盘,有 2 个分区,挂载 Linux 系统。
刷新硬盘信息
如果硬盘发生了变化但系统未识别到,比如做了分区,修复,dd 拷贝,可以用 partprobe 命令刷新分区表,使系统重新识别硬盘:
1 | sudo partprobe |
此外,如果逻辑卷未被识别,可以用 vgchange 命令激活:
1 | sudo vgchange -ay |
错误检查及修复
e2fsck 是专门用于检查和修复 ext2、ext3、或 ext4 文件系统的工具,可以检测文件系统中的不一致性和潜在错误,并尝试修复这些问题。这个工具通常在文件系统损坏或不正常关机后运行。fsck 是一个更通用的文件系统检查和修复命令,用于多种类型的文件系统(比如 xfs、btrfs等),fsck 会根据文件系统类型自动选择合适的工具来执行检查和修复操作。针对ext2/ext3/ext4文件系统,fsck 会调用 e2fsck。
基本的命令格式如下:
1 | e2fsck [选项] 设备 |
[选项]:例如,-p以只读模式运行,-y在发现问题时自动尝试修复,-f强制检查文件系统设备:这是要检查的文件系统的设备名,例如/dev/sda1
示例:使用 e2fsck 命令检查和修复文件系统错误,比如:
1 | root@rex-pc:~# e2fsck -b 32768 /dev/sdd2 |
当硬盘容量非常大时,e2fsck 可能需要相当长的时间来完成检查,且检查过程无法中断。
badblocks 用于扫描磁盘中损坏区域(坏块)的工具,识别硬盘或存储设备上的物理损坏部分。基本命令格式如下:
1 | badblocks [选项] 设备 |
常用选项:
-v:显示详细过程。这个选项会让badblocks在执行时显示更多的信息,有助于了解检查进度和结果。-s:显示进度条。这个选项会在检查过程中显示一个进度条,让用户可以直观地看到检查进度。-w:使用写入测试。这是一种破坏性测试,会写入数据到每个扇区然后读取,以此来检测坏块。注意,这会覆盖磁盘上的数据,请在数据备份后使用。-n:非破坏性测试,进行读写测试但不会覆盖数据,适用于包含有价值数据的磁盘。-o 文件名:将找到的坏块列表输出到指定的文件中。
示例(似乎要等待较长时间):
1 | root@rex-pc:~# badblocks -v /dev/sdd |
硬盘备份
如果硬盘使用时间长,经常出现坏扇区的情况,可以用 dd 命令,将其复制到另一个硬盘。
特别注意,if 和 of 端不能弄反,否则可能直接导致硬盘被覆盖或信息不完整
拷贝磁盘示例:通过 lsblk 或 df -h 确认需要拷贝的硬盘,比如将 /dev/nvme1n1 复制到 /dev/sdm:
1 | sudo dd if=/dev/nvme1n1 of=/dev/sdm bs=4M status=progress |
常用参数说明:
if=<file>:指定输入文件(Input File),也可以是设备。of=<file>:指定输出文件(Output File),同样也可以是设备。bs=<bytes>:设置每个块的大小,例如bs=4M意味着每个块是4MB。count=<number>:拷贝块的数量,用于确定总共需要拷贝多少数据。skip=<number>:跳过输入文件开头的块数。seek=<number>:跳过输出文件开始的块数。conv=<conversion>:指定转
如果硬盘较大,bs 值应该调高,比如 4M,默认值为 512Byte。
拷贝需等待较长时间,完成后,输出形如:
1 | 15261915+ records in |
此时执行 lsblk 不会看到变化,但 fdisk -l 能看到新拷贝硬盘的分区信息。也可以通过 partprobe 命令刷新分区表:
1 | partprobe /dev/sdm |
完成后,可以进行挂载,测试文件信息。
除了拷贝到硬盘,也可以拷贝为镜像,比如:
1 | dd if=/dev/sda1 of=/path/to/backup.img bs=4M status=progress |
然后进行恢复:
1 | dd if=/path/to/backup.img of=/dev/sda1 bs=4M status=progress |
故障硬盘备份
官方手册:https://www.gnu.org/software/ddrescue/manual/ddrescue_manual.html
访问加速:https://superuser.com/questions/413650/is-there-any-way-to-speed-up-ddrescue
GNU ddrescue 是一个数据恢复工具,用于从一个文件或块设备复制数据到另一个文件或块设备,特别是在源设备出现读取错误时。它尝试首先恢复好的部分,以防读取错误导致的数据损坏。ddrescue 在进行数据恢复时非常有用,特别是在处理有物理损伤或者坏道的硬盘时。
基本用法:
1 | ddrescue [options] infile outfile [mapfile] |
其中 infile 是源文件/设备,outfile 是目标文件/设备,而 [mapfile] 是用来记录进度和恢复信息的映射文件,允许中断和恢复恢复过程。
主要参数:
-a, --min-read-rate=<bytes>:指定好的区域的最小读取速率,低于此速率的被认为是坏区。-b, --sector-size=<bytes>:指定输入设备的扇区大小,默认为512字节。-d, --idirect和-D, --odirect:分别使用直接磁盘访问模式读取输入文件和写入输出文件,可以绕过缓存。-f, --force:强制覆盖输出设备或分区。-n, --no-scrape和-N, --no-trim:跳过刮擦阶段或修剪阶段,这些阶段用于尝试从坏区恢复数据。-r, --retry-passes=<n>:设置重试次数,-1表示无限重试。-s, --size=<bytes>:指定要复制的输入数据的最大大小。
以下是一个基本的 ddrescue 命令示例,它会创建一个映射文件来记录进度,以便在需要时可以恢复复制过程:
1 | ddrescue -f /dev/sdf /dev/sde rescue_mapfile.log |
注意指定日志文件,避免异常中断后重新开始。
ddrescue 会先“拯救”好的区域,也即修复 non-tried 区域,完成后开始修复坏区。坏区有两个阶段,速度均非常慢。个人尝试在 splitting 阶段终止修复,实测重启后,能正常挂载硬盘和读取数据。
1 | Trimming failed blocks... |
拷贝数据
硬盘修复完成,重新挂载代替原来的系统盘即可。如果修复后不作为系统盘,可通过 rsync 来拷贝,比如:
1 | rsync -avzP /mnt/home /home |
此外,使用 ls -ln 能查看 /home 子文件夹的 UID 和 GID。
借此恢复用户组信息,通过 groupadd 和 useradd 命令和指定参数,确保 UID 和 GID 与原始系统一致:
1 | users_info=( |
系统内核
系统内核是操作系统的核心,是启动过程中的关键组件,其负责管理系统的硬件资源、提供系统服务和应用程序接口。内核通常存储在 /boot 目录下,文件名通常是 vmlinuz 或 bzImage。
Linux 和 Windows 开机的过程:

root fs 挂载失败
在开机引导页面,option 选项下可以看到一些内核版本,比如:
1 | Ubuntu, with Linux 5.13.0-113-generic |
开机报错:
1 | Kernel Panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0) |
参考 Ubuntu 论坛给的解决方案:Kernel Panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)。
先使用 U 盘进入系统,通过 lsblk 确认系统所在分区,比如 /dev/sda2,然后挂载系统盘:
1 | MOUNT_PATH=/mnt |
一般还需要挂载 /boot 目录,比如:
1 | sudo mount /dev/sda1 $MOUNT_PATH/boot |
然后,将启动盘的 /dev、/proc、/sys、/run 挂载到系统盘:
1 | sudo mount /dev --bind $MOUNT_PATH/dev |
进入系统,执行更新命令:
1 | sudo chroot $MOUNT_PATH |
执行更新命令后,输入形如:
1 | Sourcing file `/etc/default/grub' |
如果是 initramfs 文件损坏,删除多余或损坏的内核:
1 | sudo apt-get remove --purge linux-image-5.15.0-113-generic |
安装并更新新内核:
1 | sudo apt-get install -y linux-image-6.5.0-18-generic |
完成后,取消挂载,然后重启系统。
1 | sudo umount $MOUNT_PATH/dev/pts |
如果开机 Grub 仍存在问题,可以考虑用 boot-repair 工具来修复 Grub。
此外,/etc/fstab 文件和硬盘挂载相关,也可能存在问题,可以检查内容是否匹配。
Boot-Repair
Boot-Repair 是一个用于修复引导问题的工具,可以帮助修复引导加载程序(GRUB、LILO等)的问题,包括修复 GRUB 引导程序、修复 MBR、修复启动分区等。
在 U 盘系统上安装(在挂载的系统中安装也可以,未测试):
1 | sudo add-apt-repository ppa:yannubuntu/boot-repair |
然后执行 sudo boot-repair,执行后会弹窗窗口,提示操作步骤,跟着逐步操作,点击继续,直到运行结束。
如果系统盘未挂载,执行过程会将其挂载到某个目录下,例如 /mnt/boot-sav。
一些步骤会给出关键执行代码,可以选择手动 chroot 到系统盘,再执行命令,例如:
1 | sudo chroot "/mnt/boot-sav/sdb2" dpkg --configure -a |
Root-Repair 能解决很多类型的引导问题,很多时候还是很有用的。
分区与挂载
!!! 注意,分区和挂载是非常敏感的操作,所有命令在执行前必须确保自己有足够的了解,重要数据需做好备份。
输入 lsblk (list block devices)查看当前磁盘分区情况,比如
1 | ❯ lsblk |
上边结果显示,系统中有两个磁盘设备:vda 和 vdb
vda: 40GB 的磁盘,并且它已经被分为两个分区:vda1: 1MB 大小的分区,可能是某种特殊用途的保留分区,例如EFI系统分区(但通常这类分区会更大)或者boot loader相关的分区vda2: 40GB 大小的分区,它已经被挂载在根目录(/)上
vdb: 260GB 的磁盘sr0: 光驱设备,大小378KB,通常对应实体的 CD/DVD 驱动器
将 vdb 分为两个分区,其中一个挂载到 /storage 用于存放文件,以下是具体步骤:
-
启动分区程序:
进入fdisk工具进行分区:sudo fdisk /dev/vdb -
创建新分区:
- 在
fdisk提示符下,按n创建新分区 - 选择分区类型:默认情况下是主分区(primary),默认即可
- 指定分区号:默认情况下是
1,保持默认 - 设置起始扇区:可以接受默认值,通常从 2048 开始
- 设置结束扇区或分区大小:对于一个 130G 大小的分区,可以指定
+130G
- 在
-
再次创建新分区:
- 再次按
n创建第二个新分区 - 类似进行操作
- 再次按
-
写入分区表:
- 确认分区没有问题后,按
w保存更改并退出fdisk
- 确认分区没有问题后,按
-
格式化新分区:
这里创建了两个分区/dev/vdb1和/dev/vdb2,对其进行格式化:1
2sudo mkfs.ext4 /dev/vdb1
sudo mkfs.ext4 /dev/vdb2
输入 lsblk -f,可以看到 vdb 分了两个分区,并且已经格式化了:
1 | ❯ lsblk -f |
现在,挂载硬盘:
1 | # 创建挂载点 |
mount 命令只是临时挂载分区,在系统重启后这个挂载就不会被保留。每次系统启动时,它都会读取 /etc/fstab 文件来决定挂载信息。如果需要永久挂载,可以编辑 /etc/fstab 文件,添加以下行:
1 | /dev/vdb1 /storage ext4 defaults 0 2 |
保存文件后,执行 sudo mount -a 测试是否有错误,该命令用于挂载 /etc/fstab 文件中所有未挂载的文件系统。
完成后,执行 df -h 查看当前的挂载情况
1 | ❯ df -h |
异常进程排查
htop 查看进程占用情况,或者用 smem 获取占用内存最多的进程:
1 | # sudo apt install smem -y |
逻辑卷
逻辑卷管理是 Linux 系统中的一种高级磁盘管理技术,它允许用户将多个硬盘分区组合成一个逻辑卷,以提供更大的存储空间。逻辑卷管理的好处是可以动态调整逻辑卷的大小,而无需重新分区或格式化硬盘。
其他
查看硬盘使用时间
TODO。
1 | sudo apt install smartmontools |
nvme 工具:
1 | sudo apt install nvme-cli |
分区和挂载
挂载与卸载:
1 | # 挂载硬盘 |
fuser检查特定文件、文件系统、或网络端口的占用情况,并返回正在使用它们的进程的 PID(进程标识号)fusermount是FUSE(Filesystem in Userspace)的用户空间程序,允许普通用户不用通过系统管理员权限就挂载文件系统。FUSE是 Linux 内核的一个模块,允许创建完全在用户空间的文件系统,提高了安全性和灵活性。例如,通过FUSE,用户可以挂载远程目录、虚拟文件系统等。
通常可以用 chroot 命令进入挂载设备,模拟对该设备的登录,比如:
1 | mount /dev/sda1 /mnt # 挂载系统盘 |
修改分区信息,使开机自动生效。(待补充)
1 | vim /etc/fstab |
 wechat
wechat alipay
alipay