二维码学习笔记(六) | 二维码解码
二维码笔记系列:
- 『二维码学习笔记(一) | 二维码概述』
- 『二维码学习笔记(二) | 数据分析与数据编码』
- 『二维码学习笔记(三) | 纠错编码』
- 『二维码学习笔记(四) | 信息构建与模块放置』
- 『二维码学习笔记(五) | 数据掩码与版本信息』
- 『二维码学习笔记(六) | 二维码解码』
唠唠闲话
解码是编码的逆过程,与笔记 1-5 的内容正好相反。我们先略过一遍解码流程,再展开介绍一个关键步骤:数据纠错。
跳转链接:
解码流程
下设二维码已识别,并按一定格式要求输出为矩阵。二维码矩阵为 0-1 方阵,0代表暗模块,1代表亮模块,索引从 (0, 0) 开始,以左上角为原点。
二维码检查
-
根据矩阵大小计算二维码版本:版本
k的二维码尺寸为17+4k x 17+4k,其中k的取值范围为1-40,下图为版本 3 的二维码:

-
检查位置探测图形
Finder Patterns- 三个图形分别位于左上,右上,右下
- 图形大小为
7x7 - 模块宽比为
1:1:3:1:1
-
检查包围探测图形的白色分隔符
Separators -
检查对齐图案
Alignment Pattern- 仅当二维码版本 ≥2 时存在
- 图案大小为
5 x 5,按黑-白-黑的方式包围 - 根据对齐图案位置表确定位置
-
检查时序图案
Timing Pattern- 连接探测图形的虚线,一条水平,一条垂直
- 水平时序图案位于上数第 7 行(索引6)
- 垂直时序图案位于左数第 7 列(索引6)
- 时序图案总是以暗模块开始和结束
- 时序图案可能与对齐图案重叠,但不影响,比如下图

-
检查暗模块
Dark Module,位于左下角探测图形的分隔符的右上边缘
以上为二维码最基础的要素,检查无误后,下一步读取格式信息和版本信息。
版本和格式信息
-
格式信息区域:分隔符旁边的一条模块,规则如下:
- 左上角的探测图案附近,分隔符下方和右侧的单模块条
- 右上角的探测图案附近,分隔符下方的单模块条
- 左下角的探测图案附近,分隔符右侧的单模块条
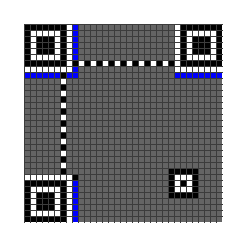
-
格式信息 = 纠错等级(2 bit) + 掩码模式(3 bits)
- 格式信息总长度为 15 比特(信息位 5 + 纠错位 10),数据按以下方式排列

- 格式信息总长度为 15 比特(信息位 5 + 纠错位 10),数据按以下方式排列
-
版本信息保留区域
- 二维码码版本 7 及更高版本必须包含两个放置版本信息位的区域
- 位于左下角探测图案上方的
6x3块和右上角探测图案左侧的3x6块 - 如下图蓝色区域
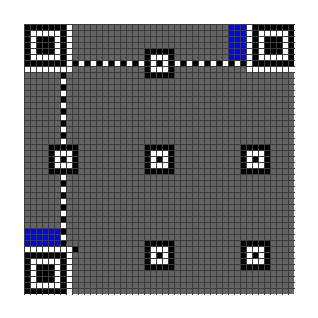
-
二维码规范要求版本信息串使用 (18, 6) Golay Code,因此,版本信息字符为 18 位字符串,由 6 位二进制字符串和 12 个纠错为组成
-
格式信息以及版本信息的解码代码(Julia)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36"""编码距离"""
hamming_distance(x::Integer, y::Integer) = hamming_weight(x ⊻ y)
hamming_weight(x::Integer) = hamming_weight(digits(x; base=2))
hamming_weight(x::AbstractVector) = count(!iszero, x)
"""版本信息解码"""
function qrdecode_version(version_code::Int)
ver_info, best_dist = -1, 18
for test_info in 7:40
test_code = qrversion(test_info)
test_dist = hamming_distance(version_code, test_code)
if test_dist < best_dist
best_dist = test_dist
ver_info = test_info
elseif test_dist == best_dist
ver_info = -1
end
end
return ver_info
end
"""格式信息解码"""
function qrdecode_format(fmt_code::Int)::Int
fmt_info, best_dist = -1, 15
for test_info in 0:31
test_code = qrformat(test_info)
test_dist = hamming_distance(fmt_code, test_code)
if test_dist < best_dist
best_dist = test_dist
fmt_info = test_info
elseif test_dist == best_dist
fmt_info = -1
end
end
return fmt_info
end
读取版本信息后,与二维码尺寸进行比较,如果不匹配,则报错或重新识别。
提取数据位
所有检查无误后,按笔记 5 的规则施加掩码,并按笔记 4 的方式提取数据区的比特。
数据还原
得到数据位(数据模块+纠错模块)后,根据二维码版本和纠错等级“去交织”,还原数据码块和纠错码块的原本顺序。
数据纠错
使用 Reed Solomon 编码数据码块,若纠错失败,则报错,否则返回编码数据,具体算法在后边单独讲解。
数据解码
笔记 1 的逆过程,此时得到的数据内容为
1 | mode indicator + character count indicator + encoded data + pad bits |
即:模式指示符 + 字符计数指示符 + 编码数据 + 填充位
主要步骤:
- 读取头部 4 个字节(模式指示符),获取编码模式
- 根据编码模式和版本,计算字符计数指示符的长度
- 读取字符计数指示符,得到字符数目
- 根据编码模式,截取编码数据(二进制)并检查填充位是否正确性
- 根据编码规则,还原原始数据
这几个步骤大都比较简单,难点在第 4 步处理字节模式和 UTF8 模式的情况,由于两种编码使用相同的模式指示符。通常策略是先用 UTF8 模式读取数据,读取失败时(比如遇到无效字符),再用字节模式读取。
数据解码
Syndrome 纠错
-
设 为接收码字, 为信息编码, 为干扰码字且错误数 ,设
解码目的是 中计算 。
-
计算 Syndromes 如下
 wechat
wechat alipay
alipay
