Julia 学习笔记(六) | Julia 简易爬虫
唠唠闲话
最近用 Julia 打比赛和做项目(拖延好些天了orz,趁着间隙也赶紧干起来) ,趁着热乎,把近期学习的 Julia 的 IO 编程用法,以及爬虫工具整理一下。
目录:
IO 编程
TxT 基本读写
-
读取文本文件-示例
1
2
3
4## 使用 do 语法
open("file.txt", "r") do io
txt = read(io)
end形式上看和 Python 的
with open(...) as类似,但含义不同。Julia 的do语法定义了匿名函数,比如1
2
3
4
5# 等价写法
function f(io)
txt = read(io)
end
open(f, "file.txt", "r")用
read函数读取文件1
2
3# 可以写成一行
io = open("file.txt", "r")
txt = read(io, String) -
写入文件-示例
1
2
3open("file.txt", "w") do io
write(io, "Hello, world!")
end同样地,也可以先返回 IO 对象,再调用
write函数写入文件1
2
3io = open("file.txt", "w")
write(io, "Hello, world!")
close(io) -
常用参数
参数 说明 "r"读取文件 "w"写入文件(不存在时创建) "a"追加文件 (不存在时创建) "r+"读写文件 "w+"读写文件(不存在时创建) "a+"读取追加(不存在时创建)
Excel 文件读写
参考链接:XLSX.jl
一些场景需要用 Excel 文件来进行交互,比如谷歌的文档翻译。这时可以用 JuliaIO 的 XLSX.jl 工具,基于 XLSX.jl 模块,我们编写简单的 Excel 工具。
-
写入函数,将向量写在 Excel 表格第一列
1
2
3
4
5
6
7
8
9# ]add XLSX # 安装模块
using XLSX
function write_xlsx(filename::AbstractString, vector::AbstractVector)
XLSX.openxlsx(filename, mode="w") do xf
sheet = xf[1]
n = length(vector)
sheet["A1:A$n"] = reshape(vector, n, 1)
end
end -
写入函数,将矩阵写入 Excel 表格
1
2
3
4
5
6
7function write_xlsx(filename::AbstractString, mat::AbstractMatrix)
XLSX.openxlsx(filename, mode="w") do xf
m, n = size(mat)
sheet = xf[1]
sheet["A1:$(excel_colind(n))$m"] = mat
end
end这里手写了一个列索引函数
excel_colind,用于计算 Excel 列编号1
2
3
4
5
6function excel_colind(k::Int)
@assert k <= 2 ^ 14 "列数超过范围"
(k -= 1) <= 25 && return 'A' + k
(k -= 26) <= 26 ^ 2 - 1 && return ('A' + k ÷ 26) * ('A' + k % 26)
join('A' + i for i in reverse!(digits(k - 26 ^ 2, base = 26, pad=3)))
end注意
.xlsx限制的列数上界为2 ^ 14 -
读取 Excel 数据,如果只有一列返回向量,否则返回矩阵
1
2
3
4
5function read_xlsx(filename::AbstractString)
data = XLSX.readxlsx(filename)[1][:] # Any 类型矩阵
_, n = size(data)
string.(n == 1 ? data[:] : data) # 单行返回向量,多行返回矩阵
end -
本篇只演示基础用法(文档交互足够),
XLSX.jl支持操作很还多,需要再进一步学习
简易爬虫
参考链接:Julia School
演示爬取 wiki 百科词条的方法,由于不需要用
header, cookie之类的设置,教程暂不介绍
-
依赖模块,用
]安装1
2
3
4# ]add HTTP
using HTTP
using AbstractTrees
using Gumbo其中
HTTP用于请求网页,AbstractTrees, Gumbo用于解析网页和提取信息 -
获取维基词条
1
2
3
4# 获取中文词条网页
zhpage(word) = HTTP.get("https://zh.wikipedia.org/wiki/$word")
# 获取英文词条网页
enpage(word) = HTTP.get("https://en.wikipedia.org/wiki/$word") -
访问浏览器页面,右键单击检查,查看网页源代码
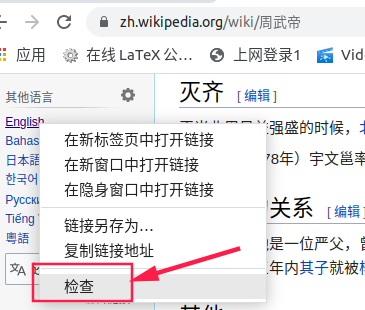
-
这一步要根据爬取需求。下边演示的是提取维基中文词条的英文名,通过左侧“其他语言”查看源代码,找到英文名所在标签

-
下一步是用
Gumbo解析网页标签,提取目标信息,由于要提取的名词有很非常明显的模式,用正则表达式处理效率会有非常大的提升 -
从英文页面提取中文名词:根据链接前的字符模式以及非贪婪匹配
?,截取中文名词1
2
3
4
5reg_en2zh = r"""<li class="interlanguage-link interwiki-zh mw-list-item"><a .*title="(.*) – Chinese?"""
function wiki_en2zh(page)
res = match(reg_en2zh, String(page))
isnothing(res) ? "" : res.captures[1]
end从中文页面提取英文单词
1
2
3
4
5reg_zh2en = r"""<li class="interlanguage-link interwiki-en mw-list-item"><a .*title="(.*) – 英语?"""
function wiki_zh2en(page)
res = match(reg_zh2en, String(page))
isnothing(res) ? "" : res.captures[1]
end最后添加关于单词的函数派发
1
2wiki_zh2en(word::AbstractString) = wiki_zh2en(zhpage(word))
wiki_en2zh(word::AbstractString) = wiki_en2zh(enpage(word)) -
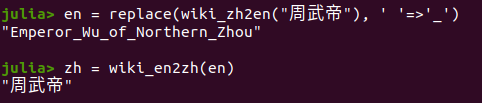
调用
wiki_en2zh和wiki_zh2en爬取相关的词条翻译1
2en = replace(wiki_zh2en("周武帝"), ' '=>'_')
zh = wiki_en2zh(en)注意单词中的空格要用下划线
_代替,这一步操作可以在enpage/zhpage中定义
注:后续根据需要再补充关于
Gumbo和AbstractTrees的介绍
异步编程
从网页数据抽取信息通常很快,但从网站下载数据则可能很慢,如果两部分内容不做任务调度,那么计算机可能大多时间都在等待下载,为此爬虫通常会用异步编程。
在顺序模式(synchronization model)中,每个子任务按照严格的顺序进行执行;而异步模式(asynchronization model) 每个子任务的执行顺序是不确定的。简单说,异步过程的执行将不再与原有的序列有顺序关系。
下边介绍 Julia 的相关函数及必要概念。
-
Task函数,定义待执行任务,输入函数要求能无参调用1
2func() = sum(i for i in 1:10^6) # 定义函数
t1 = Task(func)也可以使用宏
@task来定义任务,比如1
t2 = @task sum(i for i in 1:10^6)
用于查询任务状态的函数
1
2
3
4println(istaskstarted(t1)) # 查询任务是否已经开始执行
schedule(t1) # 开始执行任务
# 等待进行
println(istaskdone(t1)) -
Channel生成一个队列(先进先出),用put!加入元素,用take!提取元素,比如1
2
3
4
5
6f(i) = begin;sleep(10);i;end
chan = Channel(10) do c
for i in 1:100
put!(c, f(i))
end
end代码说明:
Channel(10)定义队列长度为 10,最大值可以取 `Inf- 默认参数为 0,即
Channel(0),定义不存储数据的队列,仅当take!命令被执行时,put!命令才会被执行 - 运行上边代码将执行
do函数体的内容(单参匿名函数) put!(c, f(i))执行f(i)并将结果加入队列for循环长度为 100,将会有 100 个元素会进入队列。受限于队列长度,当队列加满 10 个后,put!操作进入等待状态,直到队列有空闲位置,才会继续执行- 当函数执行结束后,队列进入关闭状态,此时不会再有新的元素加入队列,比如

- 此外,当函数内部出现错误时,队列也会进入关闭状态
- 注意:创建队列几乎是瞬间完成的,函数体内容在后台进行,不会阻塞主线程
-
上边例子中,队列元素的加入是顺序进行的,也即多次
put!操作有明确的先后关系。当处理的问题不依赖加入顺序时,可使用宏@async- 宏
@async标记的代码块会作为一个异步任务提交给任务池,然后由具体的任务调度器来决定执行和中断 - 宏
@sync表示等待代码块中所有的异步任务结束之后才结束 - 示例
1
2
3
4
5
6f(i) = begin;sleep(10);i;end
chan = Channel(10) do c
@sync for i in 1:100
@async put!(c, f(i))
end
end代码说明:
- 创建长度为 10 的队列
@async将操作丢到任务池,不必等put!(c, f(i))进行完毕便开始下一个@sync等待代码内容的任务执行结束。- 这段代码里,
@async让任务同时进行,@sync则等待代码块运行结束,避免因代码执行到末尾导致队列提前关闭
- 宏
-
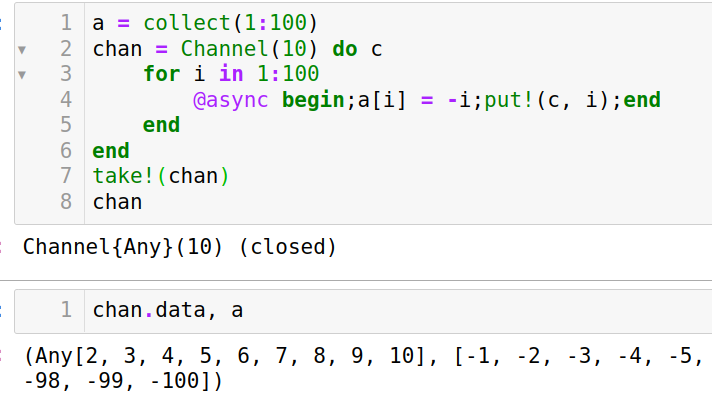
作为反例,假设没有加
@sync宏1
2
3
4
5
6
7
8a = collect(1:100)
chan = Channel(10) do c
for i in 1:100
@async begin;a[i] = -i;put!(c, i);end
end
end
take!(chan)
chan由于缺少
@sync的限制,部分put!操作未将元素导入队列,循环便执行完毕,导致队列关闭,最终元素只有 10 个,而不是 100 个
模拟多任务下载
-
规则:
- 同时下载数目 ≤ 10
- 一边下载(入栈)一边处理数据(出栈)
- 正在下载的数目 + 本地已下载数目 ≤ 15
-
模拟下载
1
2
3
4
5
6
7
8
9
10
11
12
13"""下载网页"""
function download(url)
sleep(rand(1:5))
println("page_$url downloaded")
flush(stdout) ## 清除缓存,避免运行过程不打印
return "page_$url"
end
"""处理数据"""
dosth(sth) = "process_$sth"
# 数据和结果
urls = 1:100 # 链接
res = String[] # 处理结果 -
模拟多任务下载和数据流处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17state = Channel(10) # 设置最大下载数目
pages = Channel(15) # 正在下载 + 已下载的最大数目
@sync begin
# 多任务下载
for url in urls
@async begin
push!(state, url) ## “登记”后下载
push!(pages, download(url))
take!(state) ## 下载完毕,去掉“登记”
end
end
# 数据处理
for _ in eachindex(urls)
page = take!(pages) # 读取下载数据
println(dosth(page)) # 处理数据
end
end -
本地容量设置为 Inf,保持下载数为 10
1
2
3
4
5
6
7
8
9
10state = Channel(10)
pages = Channel(Inf) # 容量设置为 Inf
urls = 1:50
@sync for url in urls
@async begin
push!(state, url) ## “登记”后下载
push!(pages, download(url))
take!(state) ## 下载完毕,去掉“登记”
end
end -
多线程执行
dosth(如果计算耗时)1
2
3
4
5
6# env JULIA_NUM_THREADS=4 julia
using .Threads
@spawn for _ in eachindex(urls)
page = take!(pages) # 读取数据
println(dosth(page)) # 处理数据
end
踩坑点
队列 state 用于限制任务开始和结束,省略将带来问题,比如
1 | pages = Channel(10) |
虽然 pages 限制了下载数目,但 put!(pages, download(url)) 先执行 download(url) 再入栈,download 不会被队列卡住
1 | page = download(url) # 先执行 |
这时候用 @async 丢入任务池,将同时执行 length(urls) 个 download 任务,同时再进行 put! 操作
引入队列 state,限制 download 的执行:
1 | # 丢入任务池后 |
 wechat
wechat alipay
alipay
