Julia 学习笔记(番外) | 从 Python 到 Julia
Julia 笔记系列:
- 『Julia 初学者指南(一) | 安装、配置及编译器』
- 『Julia 初学者指南(二) | 数据类型与函数基础』
- 『Julia 学习笔记(二) | 类型,派发与设计模式』
- 『Julia 学习笔记(三) | 广播,性能和模块』
- 『Julia 学习笔记(四) | 并行计算(预备篇)』
- 『Julia 学习笔记(番外) | 从 Python 到 Julia』
唠唠闲话
近期刷 LeetCode 题,在“先写 Python 后 Julia”的 coding 模式下体会了两门语言的差异。本篇介绍 Python 编程习惯在 Julia 中的实现,绝大多数情况下,Julia 的实现方式更灵活且有两个鲜明特性:类型派发和函数式。
Ps:LeetCode.jl 项目 提供部分 LeetCode 习题的 Julia 解答。对于有代码的问题,可以学习别人写的 Julia 代码风格和技巧,其他问题则可以自行补充和提交,两全其美。
跳转链接:类型转化,列表, 元组,字典,元素添加,删除,查找,包含,最大最小值,排序反转,逻辑判断,字符串,生成器,索引处理,向量化,IO 编程,函数式,面向对象,以及类的“继承”
数据和操作
数组部分参考了这篇教程。
-
Python 类型转化用
int, float, str,Julia 规则如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# 整数 -> 浮点数(与 Python 方法相同)
Float32(1)
Float64(2)
# 浮点数 -> 整数
# 类似 Python 的 int,但是浮点数与整数的差值必须小于精度值
Int(1.0)
# 下边报错
# Int(1.001)
# 四舍五入
round(Int, 1.1)
# 取上整
ceil(Int, 1.1)
# 取下整
floor(Int, 1.1)
# 整数,浮点数 -> 字符串
string(1), string(1.)
# 字符串 -> 整数,浮点数
parse(Int, "12")
parse(Float, "1e2") -
Python 的
list-> Julia 的Vector1
2
3
4
5
6
7
8
9
10
11
12
13
14# 与 Python 规则相同,等价写法是 Int[1, 2, 3]
l1 = [1, 2, 3]
# 列表需要指定数据类型
l2 = Float[1, 2, 3]
# 空列表必须指明类型
l3 = Int[]; l4 = Float64[]
# 取复杂性更高的类型,等价于 mat = Float64[1, 2]
l5 = [1, 2.]
# 用 `类型(数据)` 的方式转化数据格式
l6 = Vector{Float}([1,2,3])
# collect 类似于 list 命令
l7 = collect(1:5)
# 列表拼接
l8 = vcat(l1, l2)- Python 的
range(start, stop+1, step)-> Julia 的切片start:step:stop,注意规则区别 collect将可迭代对象转化为列表(Vector),类似于 Python 的list操作- Julia 的列表拼接要用
vcat或有时可以用append!,而+操作是列表的元素相加,与 Python 的+不同
- Python 的
-
Python 的
tuple-> Julia 的Tuple和NTuple1
2
3
4
5
6
7
8
9
10# 直接用圆括号定义
t1 = (1, )
# 用类型转化的方式定义
t2 = Tuple([1,2,3])
# 取前 3 个构成元组
t3 = Tuple{Int,Int,Int}(1:10)
# 上一命令的等价写法
t4 = NTuple{3,Int}(1:10)
# 元组拼接,类似于 Python 语法的 (*t1, t2)
t5 = (t1..., t2...)在 Python 中,
+运算可以拼接元组,但在 Julia 中不能直接这么操作;当然,也可以手写拼接函数1
concatenate(t1::Tuple, t2::Tuple) = (t1, t2...)
-
Python 的
dict-> Julia 的Dict1
2
3
4
5
6
7
8
9
10
11# 空字典,需指定键和键值的类型
dic = Dict{Char, Int}()
# 等同于 Dict{Any, Any}() 不建议
dic = Dict()
# 创建字典并初始化
dic = Dict{Int, Int}(1=>2, 2=>3)
# 判断是否包含键值,不能用 1 in dic
haskey(dic, 1)
1 ∈ keys(dic) # 等价写法
# 删除指定键,并返回键值
pop!(dic, 1) -
元素添加
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17data = [1, 2, 3]
# 追加一个元素
push!(data, 3)
# 追加多个
push!(data, 4, 5)
# 同 push!
append!(data, 1, 2)
# 用列表追加多个元素
append!(data, [1,2,3])
# 用混合方式,追加多个元素
append!(data, 1:5, [1,2], 3)
# 追加列表
res = [[1, 2], [2, 3]]
append!(res, [[1, 3]])
# 注意 res 的元素类型为 Vector{Int},追加信息不能直接写 [1, 3]
# 在列表前边追加
insert!(data, 1, 2)push!和append!的功能类似 Python 列表的.append和.extend,但也有区别append!追加的内容可以是元素,或者列表,迭代器等- 当
append!追加元素时,相当于 Python 的.append - 当
append!追加列表一类时,将把列表展开再加入,相当于 Python 的.extend - 此外
push!追加内容只能是元素,追加列表时,将把列表作为一个元素加入
-
元素删除操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18data = collect(1:10)
# 删除最后一个元素,返回被删除值
pop!(data)
# 删除第一个元素,返回被删除值
popfirst!(data)
# 删除指定位置的元素,返回列表本身
deleteat!(data, 2)
# 删除多个元素,返回列表本身
deleteat!(collect(1:10), 1:4)
# 删除类似名称
names = ["foo", "bar", "foo", "rex", "zong"]
deleteat!(names, findall(names, ==("foo")))
# 清空内容
empty!(names)
# 保留指定元素,删除其他
filter(==(1), 1:5)
# 删除指定元素,原地修改
filter!(!=("a"), ["a", "b", "c"])- Julia 的等号支持函数式编程,比如
==(1)相当于i->(i==1),注意括号不可省略 pop!不能删除列表的中间元素,而要用deleteat!,且返回值是列表本身- Julia 1.7 中,还增加了
keepat!函数
1
2keepat!(collect(1:10), 2:3) # 只保留指定索引部分
keepat!(collect(1:10), 2) # 只保留第 2 个元素 - Julia 的等号支持函数式编程,比如
-
定义函数,常见有四种方式
1
2
3
4
5
6
7
8
9
10
11
12# 匿名函数,相当于 Python 的 lambda
f1 = i -> i
f2 = (i, j) -> i + j
# 符合数学形式的函数定义
f3(i, j) = i + j
# 类似 Python 的 def
function f4(i, j)
i + j
end
# 支持创建函数的符号
==(1) # 相当于 i->(i==1)
≥(2) # 相当于 i->(i>=2)- 使用
function定义函数时,末尾数值将默认作为return的结果,而不需要显式写return - 此外,Julia 还支持
do语法创建匿名函数,比如
1
2
3open("xxx.txt", "r") do x
...
end等价于先将
do主体写成函数,再传入open的第一个参数1
2
3
4function f(x)
...
end
open(f, "xxx.txt", "r") - 使用
-
查找,Python 的
.index-> Julia 的findfirst等函数1
2
3
4
5
6
7
8
9
10
11
12
13
14data = collect(1:5)
# 第一参为函数
# 返回计算为真的第一个位置
findfirst(==(2), data)
# 找不到时,返回 nothing
findfirst(==(6), data)
# 在字符串中匹配字符
findfirst('a', "abca")
# 从后往前匹配
findlast('a', "abca")
# 匹配字符串,返回匹配到的切片
findfirst("ab", "abca")
# 匹配所有结果,返回列表
findall("ab", "abca")- 由于第一参支持输入函数,这些工具比 Python 的
.index能处理更复杂的问题 findall不支持直接匹配字符findall('a', "abca"),而要用findall(==('a'), "abca")
- 由于第一参支持输入函数,这些工具比 Python 的
-
Julia 提供了很多“包含”关系的函数
1
2
3
4
5
6
7
8
9# 判断元素是否在列表中
1 in [1, 2, 3]
1 ∈ [1, 2, 3] # \in + <tab>
# 判断元素不在列表中
1 ∉ [1, 2, 3] # \notin + <tab>
# 判断子集
[1, 2] ⊆ [1, 2, 3] # \subseteq + <tab>
# 函数式
filter(∈(1:2), [1, 2, 3])相关表格如下,其中最后两个符号没有定义函数
函数 快捷键 ⊆\subseteq + <tab>⊈\subseteq + <tab> + \not + <tab>⊇\supseteq + <tab>⊉\supseteq + <tab> + \not + <tab>∈\in + <tab>∉\notin + <tab>∋\ni + <tab>∌\ni + <tab> + \not + <tab>⊂\subset + <tab>⊄\subset + <tab> + \not + <tab> -
最大最小值
1 | data = [1, 2, 3] |
函数式用法:Python 的 max 返回取值最大的数值(定义域),而 Julia 的 maximum 返回最大函数值(值域)
1 | ## Python 情形 |
通过论坛发现,Python 类似功能可以用 findmax 或 argmax 实现,不过需要 Julia 1.7 版本,较低版本的实现方式相对绕一点
1 | # Julia 1.6 及以下版本 |
- 排序,反转
1 | # 类似 Python 的 reversed,但返回数据而不是生成器 |
- Julia 中与或非为
&&, ||, !而不能用and, or, not - 算符
!支持函数式,比如!f等价与g(...) = !f(...)
布尔值构成的列表类型为BitVector或Vector{Bool},结合索引可以有妙用,比如
1 | b = collect(1:8) |
-
常见算符,注意与 Python 的区别
1
2
3
4
5
6
7
8
9
10
11
12# 下整除,输入 \div + tab 键,对应 Python 的 //
2 ÷ 3
# 异或 \xor,对应 Python 的 ^
2 ⊻ 3
# 与或非,异或 \xor, 同非 \nor, 与非 \nand
&, |, ~, ⊻, ⊽, ⊼
# 乘方,对应 Python 的 **
2 ^ 3
# 问号表达式,类似 expr1 if true else expr2
true ? expr1 : expr2
# 代表有理数 1/2
1 // 2 -
字符串操作,注意双引号
""代表字符串,单引号''代表字符,而在 Python 中二者没有区别1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29# 字符串拼接,对应 Python 的 +
"abc" * "def"
# 字符串复制,对应 Python 的 *
"abc" ^ 3
# Julia 的字符串允许换行号,而 Python 需要三个引号
"
多行字符串"
# 左切,对应 Python 的 .lstrip
lstrip("---abc---", '-')
# 右切,默认去除空格
rstrip("---abc---", '-')
# 第二参允许用列表代表除去多个,但不能用字符串
strip("-*-abc-*", ['-', '*'])
# 使用 $ 在字符串中插入变量
"1+1=$(1+1)"
# 字符运算按 ASCII 表和 Unicode 进行
'a' + 1 == 'b'
# 字符支持切片操作
collect('a':'z')
# 判断是否包含字符
'a' in "abc"
# 判断是否包含于字符串,注意不能直接用 in
occursin("ab", "abc")
# 函数式用法,筛选 "abcd" 的子串
filter(occursin("abcd"), ["abc", "def"])
# 判断是否包含该字符串
contains("abc", "ab")
# 函数式用法,筛选包含 "ab" 的字符串
filter(contains("ab"), ["abc", "def"])相关函数还有
split, join, replace等就不一一演示了,其中replace支持正则匹配,比如1
2# 用 `r""` 代表正则表达式,如果需要提取结果,替代结果使用 s""
replace("Dog chase Cat", r"(.*) chase (.*)" => s"\g<2> is chased by \g<1>")关于 Python 和 Julia 的正则表达式区别,参考这篇正则表达式 | Python/Julia/Shell 语法详解
-
生成器和
for循环1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 列表生成器,类似 Python 的语法
[i for i in 1:9]
# Julia for 循环中的 in 可以用 = 代替
[i for i = 1:9 if i < 6]
# 迭代器
(i for i in 1:9)
# 多元列表循环,注意循环变量要用括号包住
for (i, j) in zip(1:3, 1:5)
println(i,j) # 打印 3 次
end
# 双重 for 循环的简写,注意中间用逗号隔开
for i in 1:3, j in 1:5
println(i,j) # 打印 3 * 5 = 15 次
end
# for 循环临时创建变量为内部变量
# 外部查看 i, j 将报错
print(i, j)Julia 的
for循环中,无论是生成器形式还是一般形式,变量i,j与外部不共享;而 Python 生成器中的i与外部不共享,for循环的i与外部共享 -
索引处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15data = collect(1:10)
# 获取切片而不创建新对象
# 创建二维数组
mat = fill(1, 3, 4)
# 用 CartesianIndices 创建索引集
inds = CartesianIndices(mat)
# 创建索引
I, J = CartesianIndex.([(1,1), (1,2)])
# 判断索引是否越界
I + J ∈ inds
# 用 eachindex 遍历数组
for i in eachindex(mat)
mat[i]
end- 和 Python 一样,Julia 的切片将创建新对象,但用
@view可以读取原内存片段 @view获取切片而不创建新对象,这一特性有许多妙用,比如实现快速排序算法时,传值不需要传递索引- 用
CartesianIndices获取索引信息,这种操作可读性更好,且利于一般化处理 - 用
eachindex代替切片for i in 1:length(data)更直接 - 值得注意的是,Julia 中的矩阵是列优先存储,也即按
mat[1, 1], ..., mat[n, 1]的顺序。在遍历 Julia 数组时,因尽量按内存数据进行,以提升运行效率。
- 和 Python 一样,Julia 的切片将创建新对象,但用
-
Julia 的向量化
1
2
3
4
5
6
7f(i) = i ^ 2
# 用 . 代表向量化
f.(1:4) # [1, 4, 9, 16]
# 与上一命令等同
map(f, 1:4)
# 使用宏 @. 声明运算为向量化,效果等同于 f.(1:4) .+ 2Julia 的列表做加减运算等同看成点集的运算
1
2[1, 2] + [2, 3] # [3, 5]
[2, 3] - [1, 2] # [1, 1]使用向量化时,可以用
Ref将某些数据看成整体,比如1
2
3nums = [[1,2], [2, 3], [4, 5]]
# nums .- [1, 2] # 计算报错
nums .- Ref([1, 2]) # 将 [1, 2] 看成标量 -
其他函数
1
2
3
4
5
6fill(2, 3, 3) # 生成常数矩阵
zeros(2, 3) # 生成浮点零矩阵
ones(Int, 4) # 生成整数向量
rand(3) # 生成 3 个浮点数
rand(Int, 5) # 生成 5 个整数,范围 -2^64 -> 2^64 -1
rand(1:10, 3) # 从 1:10 中随机取 3 个数
IO 编程
内容参考官网教程。
基础部分
-
读入和输出
1
2
3name = readline()
println(name) # 换行打印
print(name) # 不换行打印Python 版的
print可如下实现1
2
3
4
5
6function pyprint(args...; SEP::String = " ", END::String="")
for (i, s) in zip(args, fill(SEP, length(args)))
print(i, s)
end
print(END)
end一些场景中,
println可能会等待循环结束才输出,这时可以用flush(stdout)强制输出。 -
标准信息流
1
2
3
4
5stdout # 标准输出信息流
stderr # 标准错误信息流
stdin # 标准输入信息流
## 三者都是抽象类型 IO 的子类
@. typeof([stdout, stderr, stdin]) <: IO -
文件读写操作,两种语法
1
2
3
4
5
6## 基本语法
open(f::Function, args...; kwargs...)
## 使用 do 语法
open(args...; kwargs) do x
...
end示例,
do语法定义函数,并放在第一参1
2
3
4
5
6
7
8
9## 使用 do 语法
open("myfile.txt", "w") do io
write(io, "Hello world!")
end;
## 等价表述
function f(io::IO)
write(io, "Hello world!")
end
open(f, "myfile.txt", "w") -
mode常用参数模式 描述 关键字定义 r read none w write, create, truncate write = true a write, create, append append = true r+ read, write read = true, write = true w+ read, write, create, truncate truncate = true, read = true a+ read, write, create, append append = true, read = true
处理数据流
-
除了
write还有其他几个函数支持 IO 写入1
2
3
4
5open("tmp.txt", "w") do io
print(io, "hello ") # 写入到文件
show(io, "world!") # 写入到文件
print("hello world") # 输出到信息流
end
-
当
open第一参的函数省略时,将返回IO变量1
open(filename::AbstractString, [mode::AbstractString]; keywords...) -> IOStream
先新建
IO数据流,读写操作完毕再保存,比如1
2
3
4
5
6
7# 以写方式打开
io = open("tmp.txt", write=true)
write(io, "hello world") # 返回写入的字符数目
;cat tmp.txt # 此时修改未保存
close(io) # 保存修改
;cat tmp.txt # 文件已改动
rm("tmp.txt") # 删除文件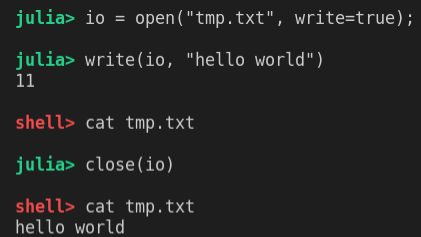
-
如果不想创建临时文件,可以使用缓冲区处理 IO 数据流(目前较少用到)
1
2
3
4
5# 创建缓冲区,默认可读可写,无上界,数据类型为 UInt8
io = IOBuffer(UInt8[], read=true, write=true)
write(io, "write into buffer ", b"zone") ## 写入内容
io.size # 查看缓冲区长度
String(take!(io)) # 将所有内容取出,并转为字符串形式
文件操作
- 几个实用变量 这些变量编写脚本时有很大用处,比如执行
1
2
3Base.PROGRAM_FILE # 文件的相对路径
Base.source_path() # 文件的绝对路径
Base.source_dir() # 查看路径名这一操作可以确保在不同位置执行这一脚本,都能正常运行(只要脚本位置放置准确)1
cd(Base.source_dir()) # 切换到脚本所在目录
函数式编程
-
谈到函数式编程,就不得不提到
Mathematica,我们先用 Julia 实现 MMA 里的一个有趣设定1
2
3
4
5
6
7
8
9Base.@kwdef mutable struct MMA
name::String = "f"
show::String = "f"
end
Base.show(io::IO, f::MMA) = print(io, f.show)
(f::MMA)(args...)::MMA = MMA(f.name, "$(f.name)($(join(args,", ")))")
Base.:(+)(f::MMA, g::MMA) = MMA(f.name, "$(f.show) + $(g.show)")
# 初始化函数 f 和 g
f, g = MMA(), MMA("g", "g")此处定义的结构体
MMA可以抽象地解释函数作用后,发生的什么事情,比如

-
reduce类似 MMA 的Fold1
2
3
4
5
6
7foldl(=>, 1:4) # 左结合律下,依次调用
# f(f(f(1, 2), 3), 4)
foldr(=>, 1:4) # 右结合率
# f(1, f(2, f(3, 4)))
reduce(=>, 1:4) # 类似 foldl,但不保证左结合率
reduce(f, 1:3; init='i') # 带上初值
# f(f(f(i, 1), 2), 3)
注意reduce在满足结合律下才能使用,否则结果可能错误

-
mapreduce(f,g,data)等同于reduce(g, f.data)1
2
3mapreduce(f, g, 1:3)
reduce(g, f.(1:3))
# g(g(f(1), f(2)), f(3)) -
filter过滤数据,类似 MMA 的Select1
filter(isodd, 1:10)
-
do语法,创建匿名函数,并作为调用函数的首参,且支持类型派发1
2
3
4
5
6
7
8func(data) do x::Vector
...
end
# 等同于
function f(x::Vector)
...
end
func(f, data) -
其他函数。。。等待补充
面向对象
更新:据说 ObjectOrient.jl 模块提供了更好的面向对象编程体验,但是我还没用过,有兴趣的可以试试
Julia 不支持面向对象编程,但借助类型系统和派发,能实现面向对象能做的绝大多数内容,举个例子
-
用结构体定义点集
1
2
3
4
5## 定义结构体,并用 @kwdef 定义初值
Base.@kwdef struct Point
dims::Int = 1
data::Tuple = (0, )
end -
Python 初始化
__init__-> Julia 多重派发,定义两种初始化1
2
3
4# 输入 Point((1,2,3)) 时
Point(data::Tuple) = Point(length(data), data)
# 输入 Point(1,2,3) 时
Point(args::Int...) = Point(length(args), args) -
Python 的显示
__repr__, __str__->Base.show1
2
3Base.show(io::IO, p::Point) = print(io, p.data)
p = Point(1, 2, 3)
string(p)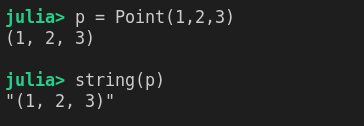
-
加法重载
__add__->+1
2
3
4
5
6
7function Base.:(+)(p1::Point, p2::Point)::Point
p1.dims != p2.dims && throw("dimension not matched!")
Point(p1.data .+ p2.data) ## 借助向量化
end
p1 = Point(1,2,3)
p2 = Point(0,-1,2)
p1 + p2
-
重载减号和负号
__sub__, __neg__->-1
2
3
4
5
6
7
8
9## 重载减号
function Base.:(-)(p1::Point, p2::Point)
p1.dims != p2.dims && throw("dimension not matched!")
Point(p1.data .- p2.data)
end
## 重载负号
function Base.:(-)(p::Point)
Point(0 .- p1.data)
end -
Julia 的
+-/*&|!%等符号都属于函数,重新定义即可,特殊符号支持通过 LaTeX 输入。符号的“运算位置”不能更改,比如*为二元运算符,无法定义为形如*p的调用方式,相关讨论见这里。此外 Julia 提供了相关的宏@infix,但不适用与1.x版本。
类的继承
Julia 的具体类型不能被继承,这种设定带来的好处远大于其弊端。但一些情况下,为了增加代码的复用性,可以用宏来实现“继承”,参见 ReusePatterns.jl 以及相关讨论。
为了实现“类的继承”,比较 “Julian” 的方式有两种,假设 B 要继承 A:
- B 将 A 当成属性,用宏
@forword把与 A 相关的函数重新定义一遍 B 的版本,函数调用时只是把其中的属性 A 拿出来 - 定义“拟抽象”类型,介于抽象类型与具体类型之间,增加一些规则限定。
示例一,回退
-
定义结构体
Book1
2
3
4
5
6
7
8
9using ReusePatterns
##### Alice's code #####
struct Book
title::String
author::String
end
Base.show(io::IO, b::Book) = println(io, "$(b.title) (by $(b.author))")
Base.print(b::Book) = println("In a hole in the ground there lived a hobbit...")
author(b::Book) = b.author -
定义结构体
PaperBook,并继承Book的方法1
2
3
4
5
6
7##### Bob's code #####
struct PaperBook
b::Book
number_of_pages::Int
end
pages(book::PaperBook) = book.number_of_pages -
定义结构体
Edition继承PaperBook的方法1
2
3
4
5
6struct Edition
b::PaperBook
year::Int
end
year(book::Edition) = book.year -
初始化结构体
Edition,并使用已有的方法1
2
3
4
5
6
7
8##### Charlie's code #####
book = Edition(PaperBook(Book("The Hobbit", "J.R.R. Tolkien"), 374), 2013)
print(author(book), ", ", pages(book), " pages, Ed. ", year(book))
# J.R.R. Tolkien, 374 pages, Ed. 2013
print(book)
# In a hole in the ground there lived a hobbit... -
使用宏
@forward((PaperBook, :b), Book)时,先识别与.b相关的函数,接着为函数派发PaperBook的版本,新函数调用时直接以.b作为参数。 -
使用缺陷:
- 如果涉及的方法数量非常多,或者方法定义分布在多个模块中,应用可能会很麻烦
- 这种组合不是递归进行的,假设 B 继承 A, C 继承 B ,则 C 在初始化时要把 A 和 B 都先初始化,当继承的对象很多时,这将会非常不方便
- 每个组合层引入了少量开销,从而导致性能损失
示例二,拟抽象类型
更自然的方式是使用宏 @quasiabstract ,暂略。
 wechat
wechat alipay
alipay

