Ubuntu 教程(三) | shell 编程入门
唠唠闲话
shell 脚本能极大简化琐碎的电脑操作,本篇笔记整理自 B 站视频:2020 全新 shell 脚本从入门到精通实战教程以及作者的主页,笔记目录
基础知识
脚本编写规范
-
规范的脚本应指定编译器,以及作者,时间,说明,版本号等信息,利于理解脚本的用途
1
2
3
4
5
# author: xxx
# date: xxx
# description: xxx
# release: x.x.x -
脚本首行指定编译器,示例如下
1
2
3
4
#!/usr/bin/env bash
#!/usr/bin/python3
#!/usr/bin/env python#在 Bash 中代表注释,但#!例外,其具有特殊含义- 编译器的路径有误时,运行将报错
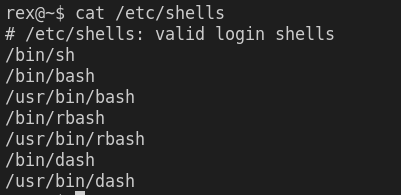
- 用
cat /etc/shells可以查看支持的 shell
-
脚本通常的运行方式,示例
1
2
3
4
5
6
7
8
9
10## shell 文件
bash test.sh
sh test.sh
source test.sh
## 其他编译器脚本-比如 Python
python test.py
## 先用 chmod 赋予权限,再用 ./test.sh 运行
chmod test.sh
./test.sh赋予执行权限的文件,直接执行时,编译器根据首行
#!确定执行环境 -
chmod命令参数解析u代表用户,+代表增加权限,x代表执行权限chmod u+x赋予该文件所属者的执行权限- 默认
chmod +x等价于chmod a+x,赋予该文件被所有用户的执行权限 - 关于
chmod更细致的介绍参考这里(后续用到再展开)
初学不熟悉时,可以用 man + <命令> 查看命令的详细用法(manual)。
符号和历史命令
-
常见符号及含义
命令 含义 cd ~进入用户主目录 cd -返回上一次的目录 $变量内容提取符 &后台执行(暂未用到) *通配符,匹配所有 ?通配符,匹配单个 \转义字符,比如 \*将通配符转义回乘法符号;用于分割一行代码中的多条命令 `` 反引号,将引号内容视为命令 ''单引号,代表字符串,内部 $解析为字符串""双引号,代表字符串,内部 $会解析为变量$?返回上一命令的退出值 $_执行最后一条命令 -
执行历史命令
!!!执行上一命令

history查看历史命令

!配合history,执行匹配的最近命令

管道和重定向
参考菜鸟教程,相关语法对空格不敏感
-
重定向
>输出重定向,比如pwd > 1.txt将当前路径打印到文件中(覆盖)>>追加方式的输出重定向<输入重定向,比如wc -l < 1.txt将文本作为输入,调用命令wc进行统计,参数-l统计行数
-
特殊的输入重定向方式
<<,示例如下,注意EOF顶格写,末尾的EOF前后不能加字符

-
EOF是 end of file 的缩写,<<也可以接其他字符串,比如

-
/dev/null文件黑洞,例如pwd > /dev/null不显示输出cat /dev/null > file将file内容清空
-
管道
|,将左侧输出作为右侧命令的输入1
2cat /etc/passwd | grep "root" # 将密码串输入到 grep,截取带 root 的密码
grep "root" < /etc/passwd # 等价方法 -
信息流的操作总结
伪代码 意义 left > right将左侧命令标准输出(stdout) 写入到右侧文件中 left < right将右侧文件作为左侧命令的输入 left right将右侧视为字符,作为左侧命令的输入 left <<EOF...EOF在右侧输入多行字符串,作为左侧命令的输入 left | right管道左侧命令的标准输出,作为右侧命令的输入 -
示例,编写脚本文件
test.sh1
2
3
4
5
read name
echo "your name is $name"
read para
echo "input parameter: $para"手动输入多次参数,等同于用
<<EOF将多个参数分行写入,一次输入
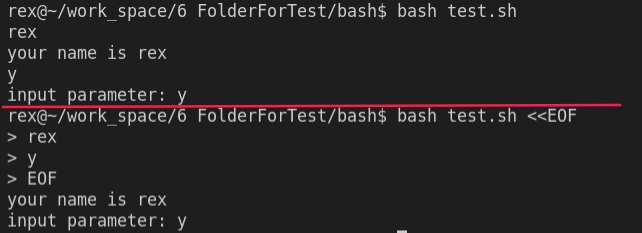
用echo+ 管道可以实现相同效果

数学运算
-
expr做数学运算,命令对空格敏感,例如expr 1 + 2输出 3expr 1 - 2输出 -1expr 1 \* 4输出 4,注意必须使用转义字符\*expr 2 / 3输出 0 ,expr仅支持整数运算,除法取下整除
-
使用双小括号计算表达式
((表达式)),其对空格不敏感且乘法*不需要转义,但同样只支持整数运算1
2
3((a = 1))
((a++))
echo $a, $((a+1)) # 输出 2, 3括号内部,变量不需要用
$符号,括号外部,$用于读取表达式结果 -
使用计算器
bc,命令对空格不敏感- 命令行输入
bc进入计算器 a = 1赋值,变量默认值为 02.3 / 2返回 1,商默认取整数scale = 2设置除法运算保留小数点后两位
- 命令行输入
-
示例,计算
10^3 / 13,并保留两位小数1
2
3
4
5
6
7# 方法一,使用管道
echo "scale=2;10^3/13" | bc
# 方法二,使用 << 重定向
bc <<EOF
scale = 2
10 ^ 3 / 13
EOF使用管道更加简洁,且方便配合格式打印,比如

脚本退出
使用 exit <整数> 命令退出脚本,整数范围为 0-255,默认退出值为 0
编程基础
输出与输入
-
echo用于输出,常见参数有:-n不要在最后自动换行-e解释转义字符
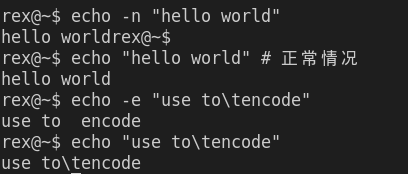
-
echo会自动忽略输入前后的空格,分隔用的多个空格等同于一个(类似 Markdown 或 LaTeX 的规则)1
2
3
4## 示例
echo 1 2 3 | wc -m # 输出结果 6
echo 1 2 3 | wc -m # 输出结果 6
echo "1 3" | wc -m # 输出结果 7 -
echo格式化打印的语法如下- 基本语法:
echo -e "\033[<底色>;<字体色><正文>\033[<字体效果>" - 示例:
echo -e "\033[41;36m底色红,字体天蓝,下划线\033[4m"

- 基本语法:
-
参数说明
- 字背景颜⾊范围:40–47
- 字颜⾊范围:30m–37m
1
2
3
4
5
6# 背景色
40 ⿊底,41 红底,42 绿底,43 ⻩底,44 蓝底,45 紫底,46 天蓝底,47 ⽩底
# 字体颜色
30m ⿊⾊字,31m 红⾊字,32m 绿⾊字,33m ⻩⾊字,34m 蓝⾊字,35m 紫⾊字,36m 天蓝字,37m ⽩⾊字
# 常用控制选项
0m 关闭所有属性,1m 设置⾼亮度,4m 下划线,5m 闪烁,7m 反显,8m 消隐 -
read用于命令行读入,语法为read f1 f2 ...,读入一行数据,按分割符赋值给变量f1, f2, ...,在变量前可使用以下参数常用参数 参数释义 -s设置输入内容的隐藏显示 -t后接整数,设置输入等待时间(单位秒),空格可有可无 -n后接整数,输入最大长度 -p后接字符串,打印提示信息(代替 echo作用) -
示例:编写脚本,模拟获取用户名和密码
1
2
3
4
5
6
echo -n "user name:"
read name
# echo -n "password:"
read -p "password:" -s -t 5 -n 6 pw
echo -e "\nuser name is $name\npassword is $pw"其中第二处
read设置 5 秒获取等待,且密码最大长度为 6
变量相关
-
内存相关知识(拓展)
1 Byte = 8 bit1 KB = 1024 B- 依次下去,
MB, GB, TB, PB Int32代表取值范围-2^31 ~ 2^31-1的整数- 计算机中,32 位操作系统可以寻址
2^32个字节的内存范围(约4.3*10^8),64 位操作系统则可寻址2^64个字节的内存范围 - 数据处理能力的 32 位指 32 bit,即一次可以处理 4 个字节的数据;64 位指 64bit,即一次可以处理 8 个字节
- 32 位的操作系统最多支持 4GB 的内存,实质是 3.25GB;而 64 位系统理论上能够支持无限大小的内存,只要有相对应的产品和足够的内存插槽
-
shell 变量语法
- 示例:
name=2333,注意=前后不能有空格 - shell 程序中的操作默认都是字符串操作,比如
name=rex视为name="rex" - 读取变量:
$<变量名> - 特别注意:shell 中直接输入的字符都视为命令,所以定义
name=ls后,输入$name等同于输入命令ls - 如果要打印变量的内容,而不是执行变量,应用
echo $name - 删除变量:
unset <变量名>
- 示例:
-
shell 的派生关系,参考博客园:
- 用户登录到 Linux 系统后,系统将启动一个用户 shell。在这个shell 中,可以使用 shell 命令或声明变量,也可以创建并运行 shell 脚本程序。
- 运行 shell 脚本程序时,系统将创建一个子shell。此时,系统中将有两个 shell,一个是登录时系统启动的 shell,另一 个是系统为运行脚本程序创建的 shell。
- 当一个脚本程序运行完毕,它的脚本 shell 将终止,可以返回到执行该脚本之前的 shell。
- 从这种意义上来说,用户可以有许多 shell,每个 shell 都是由某个 shell (称为父 shell)派生的。
-
shell 中的变量
- 局部变量:或者用户自定义变量,在脚本或命令中定义,仅在当前 shell 实例中有效,其他 shell 启动的程序不能访问局部变量;在退出当前 shell 或者脚本时将被删除
- 环境变量:有的程序,包括 shell 启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候 shell 脚本也可以定义环境变量
- 预加载变量:每次打开 bash 时,会运行
~/.bashrc和/etc/profile等文件,预加载变量可以在这些文件中定义,其中~/.bashrc为用户自定义,/etc/profile则针对所有用户 - 在脚本中直接定义的变量,只在当前 shell 生效,如果希望子 shell 也生效,需要使用
export命令
-
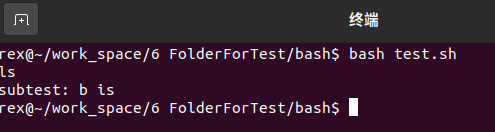
示例一:编写
test.sh和subtest.sh,并运行1
2
3
4
5
6
7
8
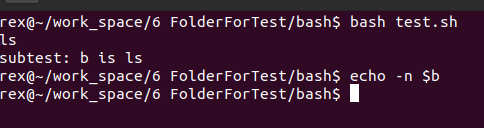
9### test.sh 文件内容 ###
#!/usr/bin/bash
b="ls"
echo $b
bash subtest.sh
### subtest.sh 文件内容
#!/usr/bin/bash
echo "subtest: b is $b"执行
bash test.sh,子 shell 中变量b为空
-
示例二:将
test.sh内容修改如下,使用export命令1
2
3
4
export b="ls"
echo $b
bash subtest.sh执行
bash test.sh,子 shell 的变量b也有定义;但注意export有效范围是子 shell,因而父 shell 中变量b仍没有定义
一般地,在 /etc/profile 或 ~/.bashrc 中定义变量,如果用 export 声明为环境变量,则用户所有 shell 都能读取该变量;如果不使用 export,则只有终端的 shell 预加载了变量,而子 shell 都不存在该变量。
数组
数组可以让用户一次赋予多个值,读取数据时只需通过索引调用,shell 中有两类数组,参考教程:CSDN 博客
- 普通数组:只能使用整数作为数组索引
- 关联数组:可使用字符串作为数组索引
-
定义数组(普通),注意等号前后不能有空格,且括号不能放在字符串中
1
2
3
4
5
6
7
8
9
10
11
12
# 用括号定义,空格隔开
array1=("a" "b" c "d")
# 用下表直接定义
array2[0]=1
array2[3]=abc
# 从命令输入赋值,多个换行制表空格视为一个,用于分割
array3=(`echo -e "1 2\t 3 \n 4"`)
# 用括号配合下标定义数组
array4=([1]=2 [3]=4)
echo -e "三个数组分别为:\n${array1[@]}\n${array2[@]}\n${array3[@]}"
echo -e "数组4的索引 ${!array4[@]}\n 数组4的内容 ${array4[@]}"数组索引从 0 开始,元素用括号
()和分隔号分开

-
基本操作
1
2
3
4
5
6
7
8array=(a b c d e) # 多个空格等同于一个
echo 获取第 0 个元素:${array[0]} # echo 后的字符串可不加引号
echo 用 * 获取数组的所有元素:${array[*]}
echo 用 @ 获取数组的所有元素:${array[@]}
echo "用 # 获取元素个数:${#array[*]}"
echo "用 ! 获取元素索引:${!array[@]}"
echo 元素切片,格式为“初始索引:结束”:${array[@]:1}
echo 元素切片,格式为“初始索引:长度”:${array[@]:1:5} -
定义关联数组,初始化必须使用下标
1
2
3
4
5
6
7
8declare -A ass_array
ass_array=([name]=rex [age]=18)
ass_array[like]=bili
echo 关联数组中的元素${ass_array[@]}
echo 关联数组中的键值:${!ass_array[@]}
declare -A ass_array2=([a]=1 [b]=2 [c]=3)
ass_array2[b]=0
echo 关联数组的数据按键值排序,键值:${!ass_array2[@]},内容:${ass_array2[@]}
注:关联数组也可以使用索引切片,但次序不好确定;普通数组也能定义一个字符串键值,定义多个会相互覆盖;操作应尽量匹配数据结构,避免不可控结果。
流程控制
程序退出值
-
在 shell 中,判断条件获取退出值,也即
exit的值,这个概念很重要,也是其他内容的基础,因而有必要先弄清楚。 -
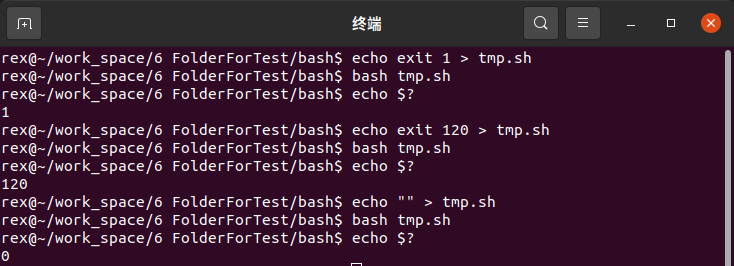
$?查看上一命令的退出值,注意退出值的有效范围为0-255,在程序中,默认exit 0,代表正常退出,非 0 值用于标记异常退出的代码
-
test命令可根据语句内容的真假,语法为test <语句>,当语句为真时退出 0,假时退出 1 -
test用于数学比较:1
2
3
4
5
6
7
8test 1 -eq 2 # exit 1 等于
test 1 -gt 2 # exit 1 大于
test 1 -lt 2 # exit 0 小于
test 1 -ge 2 # exit 1 大于等于
test 1 -le 2 # exit 0 小于等于
test 1 -ne 2 # exit 0 不等于
# 仅支持整型运算
test 1.2 -eq 2 # 报错shell 对小数的支持差,多数运算仅支持整数类型
-
类似地,
((表达式))也可用于数学表达式,当计算结果非 0 时,exit 0,结果为 0 时,exit 0。注意只支持整数运算,除法运算取下整除。1
2
3((1)) # exit 0
((1-1)) # exit 1
((1/2)) # exit 0 下除结果为 0注:语法
$((表达式))对表达式做数学计算,并返回计算结果 -
test用于文件比较和检查1
2
3
4
5
6
7
8
9test -d xxx # 当 xxx 为目录时 exit 0 否则 exit 1
test -e xxx # 检查文件是否存在,可以是目录或文件
test -f xxx # 检查文件是否存在,不能是目录
test -s xxx # 是否为目录,或者非空文件
test -w xxx # 是否有可写权限
test -r xxx # 是否有可读权限
test -x xxx # 是否有可执行权限
test file1 -nt file2 # 文件 1 是否比文件 2 更新
test file1 -ot file2 # 文件 1 是否比文件 2 更旧注意:使用
touch命令,当文件不存在则创建,已存在时不修改内容,但改动了 “最后修改时间” -
字符串比较,注意命令对空格敏感
1
2
3
4
5test string1 == string2 # exit 1 比较相等
a=xx;b=xy;test $a == $b # exit 1
test "11" != 11 # exit 1 加引号和不加一样
test -n "" # exit 1 判断是否非空
test -z "" # exit 0 判断是否为空
逻辑运算
- 与或非运算,分别为
&&, ||, !,注意算法!对空格敏感 - 注意:与或非运算也是根据程序的退出值,比如
1
2
3test 1 -gt 2 && echo "it is true" # echo 不会执行
! test 1 -gt 2 && echo "it is false" # echo 将执行
((1)) && ! ((0)) && echo 'all true' # echo 将执行
if 判断
-
语法格式一
1
2
3
4
5
6
7
8
9
10# if ... then ... fi
if [ 1 -gt 2 ]
then
echo "1 > 2"
echo command2
fi
if [ 1 -gt 2 ];then
echo "1 > 2"
echo command2
fi注意事项:
- 判断条件写在
[]中,注意表达式和括号之间要留空格 then如果和if写在同一行,需要用;隔开- 缩进不是必要,只是书写整洁
- 判断条件写在
-
语法格式二
1
2
3
4
5
6
7
8
9
10
11
12
13
14# if ... then ... else ... fi
if [ 1 -gt 2 ]; then
echo "1 -gt 2"
else
echo "1 -le 2"
fi
# if ... then ... elif ... then ... else ... fi;
if [ 1 -gt 2 ]; then
echo "1 -gt 2"
elif [ 1 -eq 2 ]; then
echo "1 -eq 2"
else
echo "1 -lt 2"
fi注意
elif也要搭配then -
elif也可用嵌套代替,只是嵌套末尾多了fi1
2
3
4
5
6
7if [ xxx ]; then
xxx
else
if [ xxx ]; then
xxx
fi
fi -
实际上,
[]语法是test命令的缩写,二者可以相互替代1
2
3
4if test 1 -eq 1; then
echo right
else echo no
fi更进一步,
if判断的部分还能用任意命令,比如1
2
3
4
5
6
7if ((1));then echo yes;fi # 语句为真,echo 执行
if ((0));then echo no;fi ## 语句为假,echo 不执行
if ls;then echo right;fi # 检查命令 ls 是否正常退出
echo "exit 1" > tmp.sh # 设置退出值 1
if bash tmp.sh; then echo yes;fi # bash tmp.sh 执行后,返回非 0,因而判断为假,echo 语句不执行 -
钻牛角尖,符号
[]只是普通的字符,比如执行1
2a=[;b=]
if $a 1 -lt 2 $b;then echo yes;fi$a$b在这里等同于[]
重点
if语法本质上是检查命令退出值,而test命令和[]语法都能根据表达式给出退出值,因而常与if搭配使用,不过[]更符合一般编程习惯。
循环控制
-
for语法一1
2
3
4
5
6
7# for ... ... do ... done
for i in `seq 1 2 9`; do # 起点 1,步长 2,终点 9
echo $i
done
for i in 1 2 3 4; do
echo $i
done说明:
in后边加数组,此处用seq命令生成数列;和if类似,do如果写在同一行,要用;隔开 -
for语法二,与 C 语言规则相同1
2
3
4
5
6
7for ((i=1;i<10;i++)); do
echo $i
done
for ((;;)); do
echo "可以只写两个 ; 但可能是死循环"
break
done说明:这里的
(())出现在for后边,与通常表达式的意义不同,通常在命令行上写((;;))会报错; -
和通常语言的流程控制一样,循环中可以使用
continue和break -
while循环,基本句式1
2
3
4
5
6i=1
while [ $i -lt 15 ]; do
echo $((i++)) # 用 (()) 进行赋值
i=$((i+1)) # 用 = 赋值
i=`expr $i + 1` # 用 expr 命令赋值
done -
while常用于读取文件,比如1
2
3
4
5
6while read p; do
echo $p
done <<EOF
file1
file2
EOF说明:
read每次读入一行,当读取到末尾时,读取失败,exit值非 0,此时while退出循环 -
until循环1
2
3
4
5i=1
until ((i>10)); do
echo $i
((i++))
done
case 语句
-
基础语法
1
2
3
4
5
6
7
8
9a=$1
case $a in
zong) echo hi, zong
;;
rex|bro) echo hi, $a
;;
*) echo hi, what is your name?
;;
esac -
使用说明:
- 左侧
xxx)匹配case检验的值 - 每个 case 最后用
;;表示结束 - 末尾用
esac表示结束(case 倒着写) - 用
|表示或者,rex|bro表示匹配rex或bro *)表示匹配余下情况
- 左侧
函数
-
函数定义语法
<函数名>(){函数内容}1
2
3
4
5
6
7f1(){
echo test1
}
# 等价写法
function f2(){
echo test2
}注意事项:
- 函数的左括号
{后边必须接空格 - 函数的右括号
}后边必须换行 - 右括号如果和语句写在同一行,必须用
;隔开 - 第二种显式写法,更符合编程习惯
- 函数的左括号
-
定义的简略写法
1
2f(){ ls;} # 注意 } 前后不能有其他字符(空格之类除外)
function f { ls;} # 括号略写,但 f 不能紧挨着 {} -
和其他编程语言不同,
shell中函数调用不使用括号1
2f(){ echo test1; }
f;f;f -
获取传入参数的方式,此外脚本本身也可以视为一个函数
命令 含义 $*返回所有外传参数 $#返回参数数量 $NN为正整数,返回第 N 个外传参数$0返回脚本名称 -
编写文件
bash.sh并运行1
2
3
4
5
jio 本名称为 $0
echo 输入数据为 $*
echo 输入参数个数为 $#
echo 输入第 1 个为 $1,第二个为 $2
-
注意
$1在函数内和函数外的区别,外部是作为脚本的传参,内部需要用f n1 n2 ...的形式将参数n1 n2 ...依次传给函数f1
2
3
4
5
6
7
8
function rex {
echo 脚本名为 $0 # 仍是返回脚本名称,而不是函数名
echo 内部调用参数:$1
}
rex # 调用函数,此时 $1 为空
echo 外部调用参数 $1 # 从外部读入的参数
rex hhh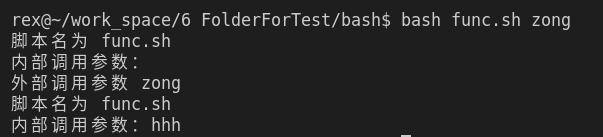
实用命令
du 查看大小
-
du 评估文件系统的磁盘的使用量,常用来查看目录大小,基本语法为
1
du [选项] [文件]
-
示例
1
2
3
4
5
6
7
8
9du # 显示当前目录下,所有子目录的大小和当前目录的总的大小
du . # 与上一写法等价
du <file> # 查看文件所占的空间,单位为 K
du -s <file/path> # 只显示总和的大小
du -h <file/path> # 以方便阅读的格式显示
du -a <path> # 文件和目录都显示
du -c <f1/p1> <f2/p2> ... # 显示指定文件和路径的大小,并统计总和
du --max-depth=1 # 设置子目录的递归深度
du|sort -nr|more # 按大小降序,通过管道组合操作 -
其他参数
参数 作用 a或-all显示目录中个别文件的大小 -b或-bytes显示目录或文件大小时,以 byte 为单位 -c或--total除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和 -k或--kilobytes以KB(1024bytes)为单位输出 -m或--megabytes以MB为单位输出 -s或--summarize仅显示总计,只列出最后加总的值 -h或--human-readable以K,M,G为单位,提高信息的可读性 -x或--one-file-xystem以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过 -L<符号链接>或--dereference<符号链接>显示选项中所指定符号链接的源文件大小 -S或--separate-dirs显示个别目录的大小时,并不含其子目录的大小 -X<文件>或--exclude-from=<文件>在<文件>指定目录或文件 --exclude=<目录或文件>略过指定的目录或文件 -D或--dereference-args显示指定符号链接的源文件大小 -H或--si与-h参数相同,但是K,M,G是以1000为换算单位 -l或--count-links重复计算硬件链接的文件
cat 用法
-
cat(concatenate)命令用于连接文件并打印到标准输出设备,参考 RUNOOB-Linux cat 命令。
-
基本语法
1
cat [-AbeEnstTuv] fileName
-
常见用法
cat file.txt查看文本文件file.txtcat > file.txt按回车后,在命令行写入文件file.txt,用Ctrl + c结束输入cat >> file.txt表示在file.txt末尾追加文本
-
参数说明
参数 参数说明 -n或--number由 1 开始对所有输出的行数编号。 -b或--number-nonblank和 -n相似,只不过对于空白行不编号-s或--squeeze-blank当遇到有连续两行以上的空白行,就代换为一行的空白行 -v或--show-nonprinting使用 ^和M-符号,除了 LFD 和 TAB 之外-E或--show-ends在每行结束处显示 $-T或--show-tabs将 TAB 字符显示为 ^I-A或--show-all等价于 -vET-e等价于 -vE-t等价于 -vT选项 -
实例
1 | # 复制 text1 到 text2 |
其他常用命令
参考菜鸟教程
-
seq生成等差数列1
2
3
4
5
6seq 8 # 生成 1 -> 8 的序列,用换行号隔开
seq 3 10 # 生成 3 -> 10 的序列
seq 1 2 10 # 生成 1 -> 10 公差为 2 的序列
seq -s , 8 # 生成序列,用 , 隔开
seq -ws "-" 12 # 生成序列,用 - 隔开,且保持数字等长(01-12)
seq -ws "-" 004 # 手动指定长度 -
sleep设置等待,支持浮点数 -
find查找文件1
2
3
4
5
6find # 查看当前路径下的所有文件和目录(包括隐藏文件)
find . # 等同于上一命令
find -name <名称> # 匹配符合名称的文件或路径
find -iname <名称> # 忽略大小写,同上一命令
find -name *.txt # 支持模糊匹配
find -type f,d # 匹配文件和路径,多个选择用 , 隔开 -
sort对数据排序1
2
3
4
5seq 10 1 -2 | sort # 按字典序排
# 10 2 4 6 8
seq 10 1 -2 | sort -n # 按数字排(取前缀最大数字 )
# 2 4 6 8 10
seq 10 | srot -nr # 相反顺序排列 -
head查看文件开头部分,默认显示前 10 行1
2ls | head # 显示前 10 个文件
ls | head -n 65 # 显示前 5 个 -
free显示内存使用情况,默认单位为 k,可设置参数,-b, -k, -m, -h -
stat + 目录/文件查看目录或文件的详细信息(innode 信息) -
wc统计数字1
2
3
4ls | wc -l # 统计行数,即当前目录下的文件数目
ls | wc -lc # 统计行数和字节数
echo w1 w2 w3 | wc -w # 统计单词数目
wc file # 统计文件信息,返回值为 行数,单词数,字节数,文件名 -
cut处理信息流1
2
3
4
5
6
7
8
9# 需指定 -b, -c 或 -f
## -b 代表字节, -c 代表字符(好像没区别,处理汉字都容易乱码)
echo abcd | cut -b 3 # 获取第 3 个字节
echo abcd | cut -b 1-3 # 获取前 3 个字节
echo abcd | cut -b 1,3 # 获取 1,3 字节
# -d 自定义分割符,-f 指定区域
pwd | cut -d "/" -f 3 # 路径裁切后获取第三个位置
pwd | cut -d / -f 2,3-5 # 输入多个时,按原来顺序排列,且用分割符隔开
pwd | cut -d / -f 5,4,3,2 # 与上一命令等价
余下内容
sed和awk命令(实战问题不足,有需要再进一步学习)grep正则表达xargs等
 wechat
wechat alipay
alipay